

Attention : la lecture de ce billet est probablement plus aisée sur sa page originale.
 Ce billet est dans le cycle « La Psychanalyse du Clavier ». Cliquez ici pour lire l'intro et les autres billets publiés.
Ce billet est dans le cycle « La Psychanalyse du Clavier ». Cliquez ici pour lire l'intro et les autres billets publiés.
Après ce grand moment de joie qu'a été la pose des accents sur les majuscules, entâmons un nouveau chapitre purement ludique et d'amitiés épistolaires interliguistiques : L'écriture dans une langue sur un clavier qui n'a absolument pas été conçu pour.
Hypothèse I : Vous êtes pressé comme un malade pour rendre votre courrier commercial en español, et vous commencez à pester contre votre clavier Français : chaque fois que vous devez mettre une tilde, un accent tonique ou même au pied de chaque phrase interrogative.
Hypothèse II : Vous êtes coincé dans un pays étranger, et quitte à demander une rallonge provisoire à votre banquier, autant mettre les bons accents sur les e, mais face à un clavier QWERTY, l'exercice vous fait passer pour une vache Anglo-Saxonne qui bredouille en Russe.
Théoriquement la bascule entre deux claviers est possible (on en reparlera), mais si le M ne jouais pas à cache-cache avec ,?, ça vous aiderait grandement…
 Savez-vous que René Goscinny, le génial créateur d'« Astérix », du « Petit Nicolas » et de milliers d'autres personnages a tapé pratiquement l'ensemble de son œuvre sur une machine QWERTY ? Celle-ci fait partie des collections de la Cité de la BD à Angoulême. Cette machine avait une particularité, c'est une machine à la disposition QWERTY internationale, qui permet d'écrire dans la plupart des langues occidentales grâce à des touches mortes. Regardez de près ces originaux vous verez que l'accent et le “e” d'un “é” ne sont pas tapés pareils.
Savez-vous que René Goscinny, le génial créateur d'« Astérix », du « Petit Nicolas » et de milliers d'autres personnages a tapé pratiquement l'ensemble de son œuvre sur une machine QWERTY ? Celle-ci fait partie des collections de la Cité de la BD à Angoulême. Cette machine avait une particularité, c'est une machine à la disposition QWERTY internationale, qui permet d'écrire dans la plupart des langues occidentales grâce à des touches mortes. Regardez de près ces originaux vous verez que l'accent et le “e” d'un “é” ne sont pas tapés pareils.
Quand j'étais en fac (c'était en 1993 et à l'époque, on avait des modems !), j'ai découvert qu'un ami envoyait des e-mails à une correspondante thaïlandaise dans sa langue, laquelle peut s'écrire avec des caractères romains mais avec une accentuation complexe ; ce mode d'écriture s'appelle le Chữ Quốc Ngữ (l'écrire est déjà un défi). Dans un jeu de caractère ASCII 7 bits, cela voulait dire une ligne de textes, pour deux lignes de caractères jouant le rôle des accents. Heureusement qu'à l'époque, les mails étaient forcément en police à chasse fixe, parce que sinon, je sais pas comment il se serait débrouillé.

Manifeste du (défunt) site şøñđëřżēıċħęŋđőmæîņĭśŧşũþėŗ.de (désolé, j'ai trop tardé à publier ce billet)
Dans une informatique dite “moderne”, il est néanmoins possible d'écrire en Français sur un clavier Anglais, ou inversement Espagnol ou Allemand sur un clavier Français sans bidouiller la disposition des touches. Raccourcis, combos complexes et au final, des milliers de recettes, mais aucune fonction standard.
Revenons aux moments héroïques
Il existait déjà dans les milieux universitaires un système de terminaux appelés “space-cadets” qui permettaient d'avoir accès aux caractères latins, mais aussi aux lettres grecques, aux symboles mathématiques et physiques. Ces engins restaient néanmoins très confidentiels, au rang de curiosité de laboratoire. Des monstres permettant d'obtenir 8000 caractères différents. Dans les années 1970s, la mémoire graphique était précieuse, inutile de dire que leur prix était stratosphérique.


Image tirées d'une page consacrée à ce diplodocus par world.std.com/~jdostale
Au début des années 1980s, presque tous les ordinateurs professionnels étaient en mode texte, où la mémoire graphique était partagée entre la représentation écran (1 octet = 1 symbole, affiché en taille constante) et la représentation graphique de la police de caractère.
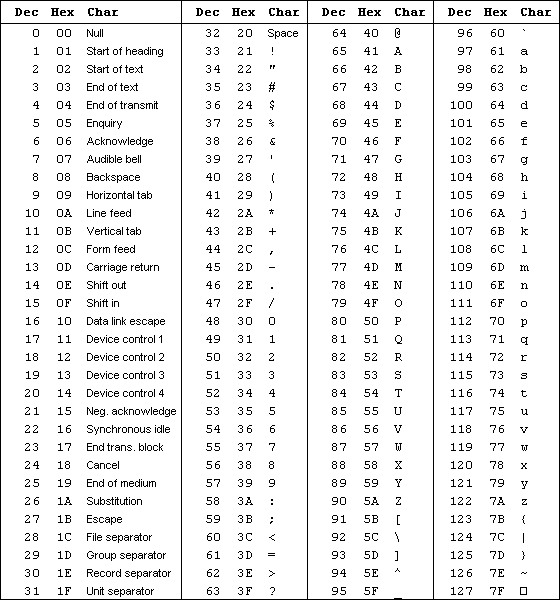
Suivant le pays où ils étaient vendus, tous les ordinateurs professionnels et familiaux jouaient sur des « pages de codes », où la partie haute des 256 caractères possibles étaient graphiquement redéfinis ①. La règle était relativement simple : Les caractères 33 à 127 étaient liés au jeu ASCII, ceux avant 32 servaient soient pour des contrôles (dont le comportement était aussi standardisé par l'American Standard Code for Information Interchange), soit des aspects semi-graphiques (genre ♥, ♣ ou ♪, à la discrétion du constructeur), donc on faisait ce que l'on voulait avec les positions 128 à 255.
{kind=link}
Avec un inconvénient évident : Si le document était écrit dans une autre langue que l'Anglais, il était peu probable qu'on aie le bon affichage final. C'était un bordel sans nom… Tenter d'ouvrir un texte venant d'un autre PC, même sauvé par le même logiciel, pouvait vous valoir des heures pour remettre les “bons” caractères. Une plaie restée purulente jusqu'au début des années 2000 ②.
 Le premier système familial à implémenter un jeu de caractères standardisé en 8 bits semble avoir été l'Amiga : le système travaillait nativement en norme ISO-8859-1 ③ et avait standardisé des combos-raccourcis afin d'obtenir des touches mortes, quelles que soient les layout de clavier. Sauf que là où les micros de la génération précidente (dite 8 bits, la machine de Commodore était une 16/32, ça va ? vous suivez ?) avaient une touche modificatrice Graphic, l'Amiga utilisait la touche Alt.
Le premier système familial à implémenter un jeu de caractères standardisé en 8 bits semble avoir été l'Amiga : le système travaillait nativement en norme ISO-8859-1 ③ et avait standardisé des combos-raccourcis afin d'obtenir des touches mortes, quelles que soient les layout de clavier. Sauf que là où les micros de la génération précidente (dite 8 bits, la machine de Commodore était une 16/32, ça va ? vous suivez ?) avaient une touche modificatrice Graphic, l'Amiga utilisait la touche Alt.
Mais cette solution n'arrangeait que les langues latines.
Pendant ce temps-là, dans un mode non latiniste...
En 255 symboles, on avait plus la place pour les caractères Cyrilliques, Chinois, Coréens, Arabes… Il se trouve que certaines de ces langues peuvent avoir 2000 caractères usuels, et 10 000 d'un usage moins fréquent. Certains de ces langues (dont le Coréen ou le Japonais) peuvent se réduire à une écriture phonétique, largement plus simple. D'autres ont des caractères dont l'aspect changent suivant le contexte ; comme l'Arabe où chacune des 28 lettres hors accentuation, comporte 4 formes d'écritures suivant qu'elles soient en début, milieu ou fin de mots, voire isolées.
Comment faire à une époque où on avait que 255 caractères chargeables dans la précieuse mémoire vidéo ? Il suffit de n'utiliser qu'une réduction de ces alphabets encombrants et hop ! Le tour était joué…
Effectivement, une telle “astuce” fut bien pénible pour les utilisateurs : vous diriez quoi si on supprimait tous les accents et les majuscules de ce texte ?
Cela ne fut pas un hasard si le Japon a longtemps privilégié les machines à traitement de texte et développé des environnements graphiques en dehors des modes textes en vogue au temps des MS-DOS.
Côté encodage, on vit une véritable explosion des jeux de caractères nationaux explosant la limite des 8 bits des octets :
- La Chine Populaire, qui avait fait le ménage dans les caractères décadents et petit-bourgeois depuis 1956, se limitant à environ 2100 sinogrammes ;
- Taïwan, qui était resté au Chinois Traditionnel et ses 47 035 sinogrammes recensés, avait ses propres jeux, souvent initié par un constructeur à son usage exclusif ;
- Le Japon en utilisait pas moins de 5 jeux différents, tous incompatibles en dehors du plan ASCII, là aussi plus créé par des industriels de leur côté que d'une manière concertée. Outre les phonétiques 46 hiraganas et 48 katagana encore casables dans les micros 8 bits, il fallait compter sur les 1945 kanji demandés dans un usage... adulte ;
- En Arabe et en Hébreu, l'arrivée de l'informatique a aidé à résoudre un problème dramatique quand il s'agissait de mixer des textes en langues Occidentales : Ces langues ne s'écrivent que de droite à gauche, ce qui obligeait à renverser en miroir toutes les mécaniques de machines à écrire. Il restait à caser les 4 formes des 28 lettres Arabes plus leurs accentuations, les 28 consonnes de l'Hébreu se contentent de s'accentuer et de parfois se lier entre elles
Pour en revenir aux claviers, il était donc financièrement et commercialement peu envisageable de faire des claviers de plusieurs centaines de touches, sans parler du formidable espace qu'il aurait fallut pour installer de tels monstres. Donc les pays Asiatiques, notamment les Japonais, instaurèrent pour leurs claviers des systèmes de sous-locales, de multiples touches-bascules (au détriment de la touche Espace, mais ça, on en reparlera), d'écriture prédictives/compilatrices, avec la possibilité de repasser rapidement au jeu ASCII de base ④.

Gros plan sur un clavier Chinois de Taïwan. Photo en Creative Commons par absentmindedprof
Il fallut attendre la démocratisation de l'e-mail à la fin des années 1980s pour que les industriels créent une norme commune. Le Consortium Unicode allait créer un standard quasi-universel. En passant à au moins 65 535 caractères différents dans un jeu unifié internationalement ⑤, on eu la place de caser tout le monde, en prévoyant des petites fantaisies : ce qui permit par exemple de créer des symboles monétaires spécifiques à tous les pays comme ₣ le célèbre Franc Français.
Et encore, pour des raisons techniques, on a souhaité regrouper dans un plan unifié les langues Chinoises, Coréennes et Japonaises. C'est le fameux groupe CJK de l'Unicode. Si un kanji Japonais, un hanja Coréen et un caractère Chinois simplifié sont graphiquement très très proches, car historiquement lié au même hanzi (sinogramme) Chinois traditionnel, on les a mis tous les quatre dans la même case ; ainsi que leurs copines hán tự Vietnamiennes et dans les autres langues de l'Asie
Cela sort du cadre du clavier, mais pour votre info, il s'agissait d'une unification tentée avant le passage à l'Unicode, et elle pose sémantiquement beaucoup de problèmes : Ce n'est pas parce qu'un caractère idéographique est un graphème dans quatre grandes langues régionalement proches qu'il veut dire la même chose.
Parait que cette situation mène régulièrement à des quiproquos…
Ça a failli être simple
Sous MS-Windows, si vous connaissez la valeur Unicode de votre caractère, il suffit simplement de maintenir Alt et de composer sa valeur Unicode sur le pavé numérique, précédée d'un zéro. Par exemple, pour “À”, il faut taper ⌈ Alt + ⌈ 0 , 1 , 9 , 2 ⌋ ⌋. C'est la méthode Alt Code, et y'a rien eu de plus ergonomique que…
Ah ? Vous trouvez pas ça simple ? Alors je suis heureux de savoir que je suis pas le seul. Dès qu'il est question de norme, et quand Microsoft n'en est pas le possesseur, ils ne peuvent pas s'empêcher de faires ce genre de gags. Ces farceurs chez Microsoft se sont donc amusés à inverser quelques correspondances. Ouvrez la Table des Caractères, et vous comprendrez. le “Š”, s circonflexe inversé, sont affublés de codes, respectivement 0138 en majuscule et 0154 en minuscule, qui n'ont rien à voir avec leur point Unicode respectifs, U0160 et U0161. Parce que la doc de Microsoft est fausse : L'entrée chiffrée se base sur le jeu de caractère Windows-1250 et “page-codes” suivants. Ce qui n'a rien à voir avec l'Unicode, mais est plus prosaïquement un bricolage éhonté de variantes non-standards de la norme ISO-8859. Résultat : ne comptez pas sur lui pour entrer du texte dans une langue d'Europe de l'Est, ou que sais-je… J'imagine la galère pour faire un énoncé de mathématiques, de géométrie ou de physique avec une usine à gaz pareil.
Au pire, vous pouvez vous rabattre sur le clavier English International, mais vous perdrez la disposition AZERTY.
Halleluia Compose
 La touche Compose sous X-Window, donc sous Linux, est àmha une trouvaille absolument géniale. Faire par exemple un début de phrase interrogative espagnole avec le point d'interrogation renversé “¿”, se fait en appuyant ⌈ Compose , ? , ? ⌋. Nan, mauvais exemple. Disons que vous voulez faire un “ŝ”. Ah ben non, avec la touche circonflexe, ça marche direct… Bon, disons “ş”, un s cédille, ⌈ Compose , , , s ⌋. Marrant, non ? On ne pouvait faire difficilement plus simple à apprendre. La liste des combos est impressionnante, et s'apprend par association graphique, comme les caractères complexes Coréens. C'est même paramétrable, mais faut mettre les mains dans le cambouis.
La touche Compose sous X-Window, donc sous Linux, est àmha une trouvaille absolument géniale. Faire par exemple un début de phrase interrogative espagnole avec le point d'interrogation renversé “¿”, se fait en appuyant ⌈ Compose , ? , ? ⌋. Nan, mauvais exemple. Disons que vous voulez faire un “ŝ”. Ah ben non, avec la touche circonflexe, ça marche direct… Bon, disons “ş”, un s cédille, ⌈ Compose , , , s ⌋. Marrant, non ? On ne pouvait faire difficilement plus simple à apprendre. La liste des combos est impressionnante, et s'apprend par association graphique, comme les caractères complexes Coréens. C'est même paramétrable, mais faut mettre les mains dans le cambouis.
Vous allez dire qu'une fois de plus, je fais dans le prosélytisme aigu pour mon système favori. Mais il se trouve que la touche Compose est une invention non pas d'un constructeur, mais d'un consortium international. C'est-à-dire qu'il est le fruit d'un consensus entre plusieurs groupes de plusieurs pays plutôt qu'un choix de développeurs exclusivement basés aux USA ⑥. Ce qui veut dire que des gens ont réfléchit très fort et on écouté ce que les zôtres avaient à leur dire. C'était ça ou risquer qu'ils développent leur propre industrie informatique dans leur coin.
 Sauf qu'il y a un os. Sur les ordinateurs Sun, Compose est pleinement reconnue, jusqu'à disposer de sa propre LED intégrée dans la touche pour faire comprendre qu'on est dans un mode bascule transitoire. Dans le monde PC, Compose est rarement “attribuée” à une touche sur un clavier AT. Dans le genre pénible lui aussi…
Sauf qu'il y a un os. Sur les ordinateurs Sun, Compose est pleinement reconnue, jusqu'à disposer de sa propre LED intégrée dans la touche pour faire comprendre qu'on est dans un mode bascule transitoire. Dans le monde PC, Compose est rarement “attribuée” à une touche sur un clavier AT. Dans le genre pénible lui aussi…
Certains, dont moi, lui assignent la touche R-Windows, doublon de L-Windows et idéalement placée à côté de AltGr, ce qui géographiquement réuni deux touches consacrées à l'invocation de caractères ésotériques. Malheureusement, les fabriquants de clavier commencent à la faire disparaître... Vous savez combien ça coûte en licence à sérirgaphier un logo déposé par Microsoft ?.
Mais pire que tout dans la choucroute, il se trouve que les associations ne sont pas standards. Par exemple, il se trouve que je parle très régulièrement de manga dans mon blog. Donc, par respect envers les japonisants qui me lisent, j'utilise l'accentuation longue et non circonflexe. Par exemple Tōkyō. Or le “ō” suivant les applications, s'écrit ⌈ Compose , - , o ⌋ ou ⌈ Compose , _ , o ⌋
Lingua Franca
Bref, dans aucun système n'a été prévu un système réellement simplifié. Reste l'usage de la souris pour faire appel à une table de caractère en menu contextuel. Encore une fois, le top de l'ergonomie (humour noir et désespéré).
Néanmoins, un effort à l'échelle Européenne tente de standardiser les layouts de claviers, les raccourcis et les combos. Un besoin important dans la Communauté Européenne passée de 6 à plus de 20 pays et leurs langues officielles (le Maltais dispose ainsi du “Ħ”, H à double-barre, sans compter les pays de l'Est), mais aussi grace à l'apport des jeux de caractères réellement internationaux de l'Unicode (et son représentant le plus connu, l'UTF-8).
Le site Starr.net fait sur cette page un effort de recencement des méthodes alternatives d'écritures sur une base QWERTY. Si vous êtes vraiment coincé, il existe des solutions disponibles sur le web à bookmarker, et disponible dans plusieurs langues : Le primitif Lexilogos et dans certaines situations, Google Translate propose un clavier cliquable.
Mais il y a plus simple si vous travaillez entre deux langues : Utiliser un clavier bilingue. Vous verrez dans le prochain chapitre que c'est un grand moment schyzo…
Notes de bas de page
- ① la partie haute des 256 caractères possibles étaient graphiquement redéfinis
- En général, les aspects des glyphes étaient gravées dans la ROM de la carte vidéo. Mais sur les machines de la gamme CPC d'Amstrad, les caractères numérotés 128 à 255 (en partie haute, donc) étaient carrément redéfinissables de manière logicielle même en mode purement texte, un comportement imité par la suite sur les compatibles PC lors de l'arrivée des cartes EGA, ce qui allait introduire les tristement célèbres “pages de codes”.
- ② Une plaie restée purulente jusqu'au début des années 2000
- Sérieux, retentez d'ouvrir un document MS-Word de cette époque : Si vous travailliez entre un PC et un Mac, c'était une belle galère car il fallait tout reconvertir à la main… Vous ne pouvez pas imaginer le soulagement qu'a été l'adoption généralisée de l'Unicode.
- ③ norme ISO-8859-1
- Cette version de la norme 8859 est dite “latin 1”, elle était spécifiquement orientée pour les principales langues d'Europe de l'Ouest. Elle a été remplacée par ISO-8859-15 aka “latin 9” (eh oui !) qui incluait le e-dans-l'o en majuscule et le symbole euro.
- ④ des systèmes de sous-locales [...] avec la possibilité de repasser rapidement au jeu ASCII de base
- À noter que toutes ces combinaisons pouvaient varier d'un fabricant à un autre, et donc plusieurs types de layout de clavier de bureau pouvaient exister pour la même langue dans le même pays. On revient à des délires de brevets et le travail de dactylo n'était rien de plus compliqué qu'à l'Est du Jourdain.
- ⑤ au moins 65 535 caractères différents dans un jeu unifié internationalement
- Par commodité, je ne souhaite pas aborder les plans étendus à 32 bits, très rarement utilisés. J'éviterais aussi la question des encodages comme l'UCS-2 qui y est justement très utilisé alors qu'on préfère l'UTF-8 en Europe, ou l'UTF-7 dont l'utilité concerne les messageries. J'ai rapidement abordé le sujet en parlant des espaces, et j'en reparlerais très bientôt.
- ⑥ un choix de développeurs exclusivement basés aux USA
- Ce qui, à leur place j'en ferais autant, auraient franchement préférer en rester à US-ASCII parce que tout ces étrangers, ils nous les broutent avec leurs langues étrangères à la con. Nos ordinateurs, soient tu les aimes, soit tu n'en a pas. (Cette note a été validée par Claude Guéant).
2 réactions
1 De da scritch net works - 16/08/2011, 14:32
Testez vos connaissances de développeur
pour vous faire recruter par un grand cabinet de placement de cadres informatiques. Non, en fait j'ai menti dans le titre....
2 De Da Scritch - 19/01/2016, 13:25
Machine à écrire chinoise mécanique