

Cet article est dans la série consacrée au développement de la bibliothèque cpu-audio.js et documente les affres de ses versions 5 et 6.. Dans cette série :
- Mettre de l'audio dans le web n'a pas été simple
- Reconstruire son lecteur audio pour le web (sur la version 5)
- Retravailler un lecteur web audio dans les petites largeurs
- Le blues du Web Share (english version)
- Deux couleurs bizarres en CSS
- cpu-audio.js enfin en 7.0
- Tout-terrain WebVTT pour de l'audio
- Dichotomie entre podcast et web sur l'audience
TL;DR Trop Long; Vous ne lirez pas ?
- La démo du player :
Si vous voyez ce texte, c'est que le lecteur ne s'est pas lancé, très probablement parce que vous ne lisez pas mon billet depuis mon blog
- Sauter au milieu de ce sonore d'un simple lien, même en dehors de la page
- Une autre démo avec les chapitres
- Le repository github du player
- Le site de démonstration du player, n'hésitez pas à tester le configurateur et l'édition de chapitres
- et tout ça pour une émission radio
Et si on étendait ce tag ?
 Mais revenons au moment où on a déclaré deux sources de sons, ce qui permettait le support par la totalité des navigateurs web supportant l'
Mais revenons au moment où on a déclaré deux sources de sons, ce qui permettait le support par la totalité des navigateurs web supportant l'<audio>.
Ladite balise ne venait pas seule : Elle était accompagnée d'une API très riche, permettant de suivre l'état de chargement du fichier, de changer le volume sonore, de connaitre la position actuelle de lecture et même de changer la vitesse de restitution ! En fait, rien ne vous interdit de ne pas afficher l'interface native et de construire la votre derrière.
L'occasion était trop belle : je changeais d'émission radio en lançant CPU et je lançais plusieurs projets liés en parallèle. L'idée étant que les contenus produits pour l'émission radio servent comme cas d'usage pour les projets afférents. L'occasion d'explorer ce que l'on pouvait explorer en production et en consommation écoute d'émissions radio sur internet et de jouer avec les spécificités d'une émission radio par rapport à un pure player audio du web.
Un de mes projets était de reconstruire un player audio au look un poil passe-partout, partageable/réutilisable avec d'autres sites, pour proposer des idées comme une playlist partageable.
Pointer dans le temps
En fait, l'écriture de ce player était une évolution d'une autre bibliothèque de mon crû : j'interceptais déjà les liens d'une page pour lier vers un moment dans le sonore d'une page, ce qui est bigrement utile…
…et prévu par un standard du W3C depuis 2009, les media fragments !
L'idée est simple : transposer dans le hash d'une url le principe de segmentation des paramètres query par un &, et utiliser les paires clé=valeurs, les valeurs étant séparées par des virgules clé=valeur,valeur. Le hash n'est interprété que par le logiciel client (le navigateur web), charge à lui d'optimiser finement la requête avec le serveur, en utilisant les requêtes partielles Content-Range, répondues par des HTTP 206 Partial Content.
Et, beauté de la dégradation élégante, si le hash n'est pas compris… il est simplement ignoré.
Il existe de multitudes de fragment de média possibles. Ainsi, si je veux afficher un bout de carré d'une grande image à partir des coordonnées (80,160) sur un carré de 80×80, je ferais un <img src="image.jpg#xywh=80,160,80,80" alt="" />.
Vous trouvez qu'il y a comme une similarité avec les sprites ? L'idée partait justement de là.
On retrouve des stratégies équivalentes pour les polices de caractère mais qui n'étaient pas décrites dans ce standard-là.
Soyons honnêtes : À ce jour, en natif, seules les vidéos sont considérées.
Et le standard n'a jamais été implémenté pour les sonores dans les pages, considérant que le chargement fragmenté via les requêtes Content-Range pouvait y palier. (Tu parles ! ça marche efficacement que pour les sonores encodés en CBR, sinon on tourne à la pifométrie, mais j'en causerais dans un autre billet).
Car oui, trop longtemps on a oublié que le web a été conçu pour lier entre eux des documents d'une manière pérenne, que le web sémantique va de pair avec l'espace d'adressage où est le document et qui existe à l'intérieur du document, et qu'on a la technologie pour lier à des chapitres (si on pense à utiliser le nommage id="", j'ai écrit un outil pour vous aider)…

…mais si ces technologies sont très bien implémentées pour du texte, voire des vues pour certaines PWA, il n'y avait à l'époque malheureusement aucune implémentation propre et standardisée dans les navigateurs pour lier un sonore ou une vidéo embarqué dans une page à un moment très précis via une URL. Ce qui pose de sacrés soucis, par exemple quand on veut pointer une phrase dans une émission de 4 heures. Oui, je fais parfois des émissions avec 4 heures de parlotte, et elles sont très très bien.
Il existe néanmoins des implémentations de la notation t=<secondes> sur des médias au sein d'une page sur des sites à très fort traffic :
- Vimeo et Soundcloud l'utilisent dans la partie hashtag, comme je le fais (…
#t=10) ; - Youtube et Peertube en sont très proches mais l'information temporelle est placée dans les paramètres de l'URL (…
?t=10), charge aux serveurs de vous envoyer une page directement au bon repère, et qui impose d'intercepter les modifications d'URL plutôt que seulement ceux du hash (exemple dans les chapitres de cette vidéo de Ça Fait Écho).
À noter que plusieurs notations sont autorisées pour le timecode en valeur de t= : notamment le nombre de secondes, ou la notation SMPTE HH:MM:SS.FFF très utilisée dans le monde professionnel (avec des frames d'une durée d'un millième de secondes).
Bonus que j'ai ajouté dans ma petite bibliothèque : quand on quitte une page avec un tel sonore par inadvertance (lien, formulaire, chat qui saute sur Alt et F4), ben si je fais ←back, ou si la page s'ouvre avec exactement le même sonore, j'aimerais bien qu'il reprenne exactement là où je suis. Ça serait la moindre des choses, non ?
Voilà qui m'a écrit…
Mes règles de base :
- être toujours au plus près des standards, pour ne plus revivre l'enfer d'avant leur respect, et avoir un code qui restera fonctionnel dans le temps ;
- minimalisme de code, pas de bibliothèques/frameworks externes (JS ou CSS), si on s'appuie sur un framework, vous ne pourrez jamais virer cette béquille et elle vous posera des problèmes à l'avenir ;
- si besoin de code externe, appliquer les polyfill les plus proches de ces mêmes standards ;
- pouvoir le développer avec le moins d'outils tiers (genre Bower, Less, etc...). Tout au plus des linters et des compresseurs JS et CSS ;
- par dégradation élégante, pouvoir fonctionner sur des vieux tromblons de plus de 2 ans au minimum ;
- que le lecteur natif du navigateur web puisse fonctionner et s'afficher même si votre javascript est complètement planté, car si votre site de contenus ne présente aucun contenu sans javascript, c'est qu'il est sémantiquement mauvais ;
- un design liquide, pour s'adapter à tous les styles et largeurs ;
- assurer un minimum d'accessibilité ;
- rappeler l'importance d'un bon web sémantique.
Le papa player
Alors tout ça, je l'ai braficotté dans mon coin dans une petite bibliothèque javascript. Elle faisait ça :


- code javascript avec l'excellent framework vanilla js
- en liquid reponsive web-design,
- avec i18n (
internationalization
, baille ze ouéy excuse my french) - affichage de pochette
- ajout de lien vers la page canonique du sonore
- navigation au clavier dans le sonore
- reprise à la volée si on a quitté le sonore (donc la page) inopinément au même endroit (très utile quand on lit la dernière émission dans la home du site CPU.pm, puis qu'on clique sur la page de l'émission)
- partage sur des réseaux sociaux avec le moment en cours
- avoir un contrôleur cloné pour l'entête fixé (qui apparait quand le lecteur principal n'est pas visible)
À l'usage, notre player est réellement devenu un outil très utile pour dérusher les émissions, et pas que pour moi, mais aussi pour les journalistes qui ont participé à l'émission.
Mais le code de génération est assez.. dégueu...
En plus, je voulais tenter un système de playlist centralisée (pour tous les podcasts de la radio), qui impliquait de charger la lib JS depuis un domaine précis. Très grosse erreur.
je voulais rafraichir mon projet avec les Web Components. En fait, je voulais le faire avec dès 2015, quand je lançais l'émission, sauf qu'à ce moment-là, l'ensemble Web Component n'est pas encore gravé dans le marbre et les implémentations parfois masquées dans les navigateurs.
Les WC étaient fermés de l'intérieur
J'ai jamais vu une discussion sur les WC qui n'est pas partie en couille
(@myagoo, in slack communautés-toulouse )
Bon, on va pas troller, on va y aller simplement :
 L'idée des Web Components est dans l'air depuis 2012. Il a commencé par être implémenté dans Chrome avant que le standard soit correctement validé. Puis nous eûmes soit des implémentations avec leurs propres API et concepts (ReactJS, VueJS,…) , soit des polyfills plus ou moins proches des standards (Polymer,…)
L'idée des Web Components est dans l'air depuis 2012. Il a commencé par être implémenté dans Chrome avant que le standard soit correctement validé. Puis nous eûmes soit des implémentations avec leurs propres API et concepts (ReactJS, VueJS,…) , soit des polyfills plus ou moins proches des standards (Polymer,…)
Le choix d'un polyfill au plus proche des standards me semblait évident, et je voulais utiliser le génial Bosonic de mon camarade Raphael Rougeron.
Si je radiographiais le code source d'un Web Component, je verrais ça :
<template>
<style>
…
</style>
…
</template>
<script>
class TonElement extends HTMLElement {
constructor() {
}
…
}
window.customElements.define('ton-element', TonElement);
</script>
Un motif HTML, un stylage CSS et une classe javascript pour piloter le module.
Dans l'idée de départ, le tout était enregistré dans un document .html importé dans ta page via <link rel="import" href="webcomponent.html" />
Et dans ta page, tu l'appelles comme ça :
<ton-element>
</ton-element>
Le choix de nommage est assez malin car le standard impose dans le nom d'utiliser un -, afin de ne pas se marcher sur les pieds ultérieurement.
Les Web Components sont formidables
 Et en quoi ils vont nous être bigrement utiles :
Et en quoi ils vont nous être bigrement utiles :
- ils présentent un ensemble d'API totalement standardisées par le W3C, dans 10 ans, le code tournera encore ;
- ils obligent à concevoir un design atomique : réfléchir non plus en terme d'aspect global d'une page comme on le fait pour un site, mais en briques élémentaires, indépendantes, donc réutilisables ailleurs ;
- ils peuvent se passer des frameworks de rendus pour les intégrer ; fini la panique de mettre à jour bloated code, ranger ReactJS à côté de MooTools dans l'étagère du fond ;
- il sont isolés du reste de la page avec le Shadow DOM, une API
documentfragment d'un DocumentRoot (comme une iframe) appeléeshadowRoot. L'isolation peut être stricte, mais laisse la possibilité de discuter par des points d'entrée ; - ils n'ont plus besoin de CSS reset pour nettoyer les règles venant de la CSS du site, ou de filtrer des événements sur des tagNames. À noter que les variables CSS3 passent, on s'en servira ;
- leur insertion est simple au possible, à condition que le développeur pense à la dégradation élégante ;
- mais ils peuvent inserer des éléments déclarés dans leur code d'appel HTML, ce qui permet une dégradation élégante si le Web Component n'est pas fonctionnel ;
- ils disposent d'une mécanique standard pour l'inclusion et la suppression d'une instance d'un Web Component dans une page, déjà cablée sur tout manipulation d'éléments, ce qui facilite la gestion mémoire sur les Single Page Application ;
- comme la version de javascript imposée accepte les extensions de classes, on peut construire des héritages de web-elements.
En fait, un Web Component, vous vous en serviez sûrement des prototypes via <input type="date">, <input type="range">, le tandem <summary>/<details> ou encore <video controls> , car les implémentations natives
de ces composants dans les navigateurs datent à peu près de cette période.
Dégradation élégante
 Pour moi, il me semblait absolument évident que le script doit être capable de ne pas fonctionner sans bloquer l'accès au contenu publié. Il y a milles et unes raisons que cela arrive :
Pour moi, il me semblait absolument évident que le script doit être capable de ne pas fonctionner sans bloquer l'accès au contenu publié. Il y a milles et unes raisons que cela arrive :
- La bibliothèque ne se charge pas,
- votre code est bugué,
- le navigateur client n'a pas toute les fonctionnalités nécessaires,
- le visiteur bloque volontairement tout javascript pour des raisons hygiéniques,
- le web n'est pas parcouru que par des navigateurs webs connus et le Google-bot.
Il faut donc que le lecteur audio natif reste fonctionnel, mais qu'il soit facilement capturé et caché par le Web Component. Et ses propriétés d'invocations sont extrêmement intéressantes :
<cpu-audio>
<audio controls>
</audio>
</cpu-audio>
Sur un navigateur ancien
, la balise du Web Component sera toujours interprétée, mais le navigateur ignorera sa signification sémantique. En fait, elle serait vue par un <div> que ce serait pareil. C'est un fonctionnement d'intégration par fallback qui a toujours été prôné par le W3C et qui est utilisé dans les exemples plus haut avec <object> et <audio>, et c'est ce qui permet de garder un minimum de support le temps que les navigateurs clients soient renouvelés.
La balise <audio> que j'y ai mis serait du coup intégrée normalement, et son interface graphique normalement affichée, invoquée via l'attribut controls.
Les précédentes opérations ont lieu sur un navigateur moderne, sauf que la classe TonElement liée à la balise sera invoquée via sa méthode constructor() ; méthode qui insère le shadowDom (l'interface graphique), lance les interactions avec cette interface, et retire l'attribut controls de la balise <audio> pour la cacher.
J'avais néanmoins besoin, même si les API Web Components n'étaient pas supportés, qu'un navigateur daté
profite néanmoins de la fonctionnalité d'adressage dans le temps du sonore. Ce qui voulait dire avoir une vraie politique de développement en amélioration progressive et pour cela, il fallait isoler du code ce qui concerne purement cet adressage et la gestion de l'interface graphique. Bon, dans les faits, tout n'est pas proprement isolé, mais l'essentiel y est.
Brique-olons
 Chrome avait une excellente démonstration du ShadowDOM v0 mais avait des petites craditudes derrières. Il y avait aussi la possibilité d'insérer des variables dynamiques dans la CSS et le HTML, mais l'implémentation jouait avec des rafraichissement continués en écrivant directement dans le
Chrome avait une excellente démonstration du ShadowDOM v0 mais avait des petites craditudes derrières. Il y avait aussi la possibilité d'insérer des variables dynamiques dans la CSS et le HTML, mais l'implémentation jouait avec des rafraichissement continués en écrivant directement dans le .innerHTML, avec donc d'énormes soucis de performances. Mozilla avait sa propre implémentation, les X-Tags, qui n'étaient vraiment pas facile à prendre en main. Enfin bref, fallait implémenter de façon très expérimentale, des fois pas accessible par défaut, car on allait changer pas mal de paradigmes sur lesquels les navigateurs web étaient construits.
Puis virent les BONNES nouvelles : ShadowDOM v1 fut enfin finalisé. Chrome en fit une implémentation propre. Et l'équipe de Google proposa un polyfill, WebComponentsJS, qui était vraiment au plus proche du standard des Web Components, à se demander quel intérêt on a encore à utiliser le framework Polymer.
Bon en fait, WebComponentsJS n'est pas parfait, notamment il crée des javascript inline pour émuler les HTML import et les inclusions… une réponse extrêmement mauvaise en terme de sécurité car on doit alors réduire les Content Security Policies de son site, et pour moi, réduire les fonctions de sécurité est une ligne rouge.
Il fallait attendre patiemment les implémentations natives qui n'allaient pas tarder. Le navigateur multi-plateforme qui était apparemment le plus en retard était Firefox, l'implémentation native était là, activable par des paramètres cachés car pas encore considérée comme suffisamment solide. En fait, Mozilla attendait une stabilisation de l'API, dont leur implémentation était cachée jusqu'à Firefox 63 quand il était en version nightly.
Étonnement, Safari était assez vite prêt, Apple n'étant pas pressé de rendre le web aussi puissant que les applications natives.
Il reste le support de Edge, qui habituellement adapte bien plus vite les standards que Safari. Je tiens de source sûre que Microsoft le proposera pas pour la fin de l'année, car le support demande une refacto assez conséquente.
L'interface
Voici un exemple de l'interface en mode large
:
Euh.... vous savez quoi ? Vaut mieux vous le montrer en vrai :
Pas de bol, votre navigateur ne supporte pas les Web Components
Mais voici une capture écran de ce que vous manquez :
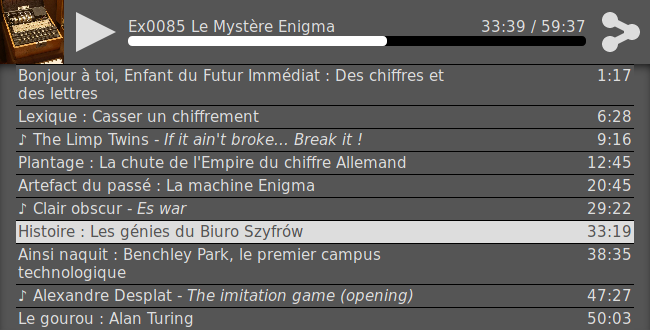
On voit le panneau horizontal standard avec la pochette, le bouton lecture/pause, le titre qui renvoie à la page canonique, le temps écoulé, la timeline (où l'appui long entraine l'apparition du mode de navigation smartphone) et le bouton d'action.
Et le panneau optionnel de chapitrage.

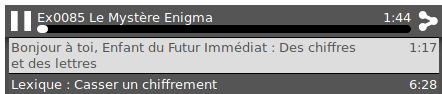
normale, et une autre dans une largeur de smartphone. Captures de début octobre 2018.
La puissance du chapitrage
 Dans les fonctions qui sont hyper-pratiques et donc je suis fier, il y a le support des chapitres.
Dans les fonctions qui sont hyper-pratiques et donc je suis fier, il y a le support des chapitres.
Normalement, il existe la possibilité de chapitrer un fichier mp3/mp4 MAIS chaque format audio a sa propre spécification et il n'est pas dit que si un sonore a deux sources différentes, qu'elles soient raccord sur les déclarations de chapitres, et donc d'avoir des données uniformes. De même, un des problèmes les plus récurrents est que celui qui a encodé le média ne pense pas toujours à vérifier que les métadonnées soient en début de fichier, car certains encodeurs partent dans l'idée que vous voulez faire du vrai stream, sans début identifiable, et donc le chapitre déclaré au moment où il apparait (c'est comme ça que les radios transposent les informations contextuelles RadioText du RDS dans leur stream mp3 sur le net).
Un sac de nœuds ? Non. Il se trouve qu'il existe un standard du W3C (dérivé des fichiers de sous-titres .srt , donc... issus du piratage, mais chut) : Les WebVTT. Et pour les exploiter, une API standard parfaitement supportée par les navigateurs peut prévenir quand on entre ou sort d'un de ces chapitres.
Il est probable que vous les ayez déjà vus à l'œuvre dans une vidéo… sauf qu'ils sont quasi jamais utilisés en audio, et donc sans interface utilisateur dans le navigateur… Jusqu'à maintenant.
Pour des raisons éditoriales, l'interface des chapitres est activée sur mon blog, pas sur le site de CPU.
De même, le player intègre désormais une fonction playlist dans une page : si une balise termine sa lecture, la lecture d'une suivante peut démarrer dans la foulée.
Ce que j'ai appris
 Plein de méthodes du DOM que je ne connaissais pas, et qui m'ont facilité le travail. Une fois de plus, on ne relit jamais assez les standards du W3C, sachant qu'ils font actuellement plusieurs milliers de pages. Une de mes découvertes, par exemple, me permet de gérer le blocage des lectures de son automatiques introduits depuis Avril 2018,
Plein de méthodes du DOM que je ne connaissais pas, et qui m'ont facilité le travail. Une fois de plus, on ne relit jamais assez les standards du W3C, sachant qu'ils font actuellement plusieurs milliers de pages. Une de mes découvertes, par exemple, me permet de gérer le blocage des lectures de son automatiques introduits depuis Avril 2018, document.hasFocus() m'évite de lancer une lecture trop tôt et d'attendre que le visiteur a cliqué dans la vue de ma page.
Plein d'événements et autres subtilités sur des balises HTML que je croyais connaitre. Comme quoi, on ne relit jamais assez les documentations officielles.
Utiliser les variables CSS3 pour pouvoir customiser l'aspect du Web Component de l'extérieur sans avoir à bricoler le code ou mettre trop d'attributs HTML dans la balise d'appel.
Modifier du balisage sur les billets descriptifs de 95 émissions de CPU.
J'avais prévu de cacher la liste des chapitres si elle a été chargée et affichée par le lecteur. À la main, et plus d'une fois, pour finalement ne pas m'en servir de suite. Quand vous allez dans vos toilettes avec votre laptop, y'a comme un signe. J'ai tiré une croix pour les 390 Supplément-Week-End et tous les autres émissions archivées. Moralité : toujours déclarer des id="" par blocs reproductibles suffisamment tôt et s'y tenir, ce qui aurait permit d'automatiser ces modifs triviales.
Garder une séparation entre les sources HTML, feuilles de style et javascript.
L'implémentation de HTML Imports restera dans les limbes pour des raisons de sécurité. Heureusement, on peut faire sans, tout en gardant la possibilité de séparer le <template>, le <style> et le javascript : Pour cela, j'ai écrit un make.sh maison crade, certes, mais il fait le taf avec un minimum d'environnement, et je vous invite à participer, il est dans le repo de ce projet.
Avoir attendu 2018 pour développer la nouvelle version m'a permis de bénéficier de :
- API enfin stabilisées et réellement standardisés ;
- meilleur support de ces standards dans les navigateurs ;
- par amélioration progressive, pouvoir toucher 50% d'audience ayant un navigateur à jour de moins de 6 mois (et avoir au moins deux navigateurs cibles multiplateformes) ;
- n'utiliser aucun polyfill ;
- modulariser pour avoir un fonctionnement possible sans le support des Web Components ;
- usage des variables CSS3, ce qui permet de pouvoir personnaliser plus facilement le player ;
- relevé deux bugs dans Firefox, 1476302 et 1476301 (yay !) ;
- passer mes serveurs en HTTP2, mais sans le mode push, faute d'un support correct du mode
HTTP 206 Partial contentou de pouvoir désactiver le push en fonction du type-mime ; - résoudre le problème posé par le blocage des autoplays sonores par Chrome (mars 2018) et Firefox (Octobre 2018).
- étoffer la doc et proposer un outil de configuration live et d'édition des chapitres
Je me suis néanmoins planté
 J'ai perdu un contributeur (désolé NerOcrO) car j'ai repris le projet ondemiroir-player de zéro à grands coups de copiés-collés et je l'ai surtout annoncé beaucoup trop tôt avant de pouvoir prendre des tiers. Cela a toujours été ma peur bleue quand j'ouvrais mon code, et le meilleur moyen est d'écrire suffisamment tôt une guideline des contributeurs pour que les règles soient posées d'entrée.
J'ai perdu un contributeur (désolé NerOcrO) car j'ai repris le projet ondemiroir-player de zéro à grands coups de copiés-collés et je l'ai surtout annoncé beaucoup trop tôt avant de pouvoir prendre des tiers. Cela a toujours été ma peur bleue quand j'ouvrais mon code, et le meilleur moyen est d'écrire suffisamment tôt une guideline des contributeurs pour que les règles soient posées d'entrée.
Il y a toujours ce souci insupportable qu'il est impossible d'essayer Safari sur iOS sans avoir un iPhone/iPad sous la main. Et d'expérience sur les interfaces, un émulateur peut être vraiment trompeur. J'en veux pour exemple le mode émulation d'appareils mobiles
de Chrome à qui il manque des API telles que navigator.share. Alors payer pour un émulateur en ligne… ahem…
Et tout ça pour arriver trop vite, ayant quasi-terminé 6 mois avant de pouvoir lancer mon player :/ Les Web Components totalement fonctionnels sont arrivés dans Firefox 63 sorti officiellement le 23 Octobre, bien après Chrome et Safari, mais la version LTS (Long Term Support) actuelle est Firefox ESR 60 et Tails utilise une version encore plus vieille. Ce qui veut dire que Firefox ESR et Tails vont voir le nouveau lecteur dans sa version fallback un petit moment : pas avant juillet 2019.

long tailJe terminerai par un tweet de @mariejulien (le gars des badges en tissu) lors de Paris Web
Question de @SkyNebula à #parisweb sur comment contribuer au libre quand on est designer, début de réponse "déjà tu peux voir si y'a un contributing md sur le repo…" 😅🤗
Vous le voyez toujours pas le problème ? Tout le monde n'utilise pas des outils de dev. Get over it. 😁
… ce qui m'a fait écrire le message d'accueil aux contributeurs extérieurs AUSSI pour les non-développeurs. Ne serait-ce pour les traductions, le graphisme, la doc, etc… Il faut que je complète encore pour expliquer comment faire sans avoir à installer d'outils via le site web de Github, notamment l'épineuse question des localisations (utiliser les .po ? un tableur ?).
Ce qui m'amène à…
L'avenir imaginé pour mon lecteur
 Oui, je sais, il ne faut pas documenter le futur d'un produit. Néanmoins, voilà ce que j'aimerais faire :
Oui, je sais, il ne faut pas documenter le futur d'un produit. Néanmoins, voilà ce que j'aimerais faire :
- avoir un vrai travail de design et d'accessibilité, et le documenter ;
- résoudre le problème du positionnement fin en tactile sur smartphone : la barre de progression n'est bien qu'à la souris sur ordi, on compense la précision par le clavier. Aucun de ces dispositifs sont sur portable… j'ai prévu une interface avec des boutons en appui long sur la timeline (ou click droit à la souris), mais c'est pas encore ça ;
- le support des règles CSS en fonction de la largeur d'un élément ;
@elementest prête pour moi, mais implémentée nulle part ; - plus de tests de non-régression ;
- encore plus de tests ;
- documenter encore plus ;
- construire en même temps que la compilation des add-ons pour des CMS communs, notamment dotclear ;
- créer des add-ons WebExtensions pour les navigateurs avec un ProtocolHandler custom pour basculer la lecture vers une application native (ex: VLC), et donc gérer les touches multimédias, ou les copier dans une clé USB à emporter ;
- créer des fonctions décentralisées, sur le modèle (ou basées sur) mastodon :
- pouvoir faire des commentaires comme pour SoundCloud mais de façon décentralisée ;
- pouvoir créer des playlists et les partager de façon décentralisé. Par exemple, lier des émissions qui ont la même thématique comme « Tout est numérique » d'Olivier Tesquet sur France Inter, « Libre à vous» de l'April, le podcast « NoLimitSécu avec la mienne, et les annoter ;
- générer des infos côté serveur comme
- un spectrogramme ;
- découper en MSE API ou MPEG-DASH (Dynamic Adaptive Streaming over HTTP), notamment pour sauter plus vite à des fragments (mais y'a des brevets dessus) puis les navigateurs Chrome et Safari se montrent très mauvais dans le chargement partiel d'un sonore via les requêtes
Content-Range; - avoir un système de pige automatique des textes, pour l'accessibilité aux sourds et malentendants. Je remercie infiniment le travail des bénédictins de l'April, se faire transcrire par eux est un honneur. Accessoirement, cela aide aussi au référencement naturel (sifflote) ;
- traduire ;
- supporter les localisations RTL (Right To Left), notamment pour les langues arabes, hébreu,… ce qui signifie renverser les icones, la timeline et.... les touches fléchées du clavier, eh oui ;
- supporter la vidéo aussi ;
- rester sous les 100Ko.
« Mais pourquoi t'embêter ? y'a les apps natives maintenant ! »
Alors oui, malheureusement, la plupart des utilisateurs d'internet sont désormais clients d'applications mobiles…
mais pour moi, le Web n'est pas mort !
Il est ce que nous en ferons : du partage, de l'accès à tous et dans le <a href=""> tous les lier. Il peut même remplacer fortement ces applications, éviter la fragmentation des langages et des frameworks, et conforter ses missions premières via les hyperliens et la décentralisation,…
Qu'on puisse mettre un marque page à un endroit, partager ce lien et donc le contexte à ses amis, dans ses billets de blogs, et retrouver le contexte si la page est publique bien plus tard (à condition que le site existe et qu'il a maintenu son plan d'adressage).
C'est un peu ce que je fais inconsciemment avec ce petit bout de code, qui ne sert qu'à une chose : rendre les sonores plus navigables et plus partageables.
L'étape suivant a été de travailler dans les petites largeurs.
5 réactions
1 De Franck - 06/11/2018, 19:24
C'est super intéressant ! Merci d'avoir pris le temps de détailler de cette façon toute la conception et le développement.
2 De Matthieu V - 07/11/2018, 08:29
Super post ! Tu apportes une très belle vision globale de ce que devrait être le développement Web !
3 De nzo - 07/11/2018, 10:07
Très bon article, j'apprécie bien le déroulé de l'argumentaire. Bonne continuation à vous !
C'est rafraîchissant de lire de bons articles complets et documentés !
4 De Da Scritch - 27/11/2018, 08:43
Excellent article par Mozilla hacks
https://hacks.mozilla.org/2018/11/t...
5 De David10 - 09/03/2021, 08:24
Super taf! Je suis en train de coder le player HTML5 natif pour l'améliorer,
malheureusement, je suis tombé sur un bug d'iOS... incompréhensible.
si quelqu'un sait pourquoi <audio> ne s'affiche pas bien sur iPhone, merci d'éclairer ma lanterne :)