

Les rétroliens (en VO : trackback) sont des IRI [NB1]
très spéciales, qui ne se visitent pas avec un navigateur, mais sont des interfaces de dialogues entre deux serveurs web, plus exactement entre deux moteurs de blogs. En clair, quand quelqu'un écrit un billet pour son blog “A”, mais veut signaler à un autre blog, “B”, que “A” a écrit un billet qui fait référence à ce que “B” a écrit dans un billet de son blog, “A” demande à son gestionnaire de blog d'envoyer un ping sur l'adresse de rétrolien attaché au billet “B”.
Si quelqu'un réagirait dans son blog à mon billet, vous aurez écrit plus bas (en-dessous des commentaires) une référence à sa réaction dans le chapitre « La discussion continue ailleurs ».
Les trackbacks ne sont pas gérés par une norme, mais un consensus entre développeurs de plateformes/systèmes de blogs. Le système fut créé par SixApart, qui en reste la référence.
Système pratique et automatisés, les rétroliens devinrent très populaires dans les systèmes de blog.
Trop.
Ils n'avaient aucune sécurité (une simple requête POST avec une IRI quelconque suffisait), aucune confirmation... Il n'a pas fallut longtemps pour que leur début de popularité fut exploité par les spammeurs. Contrairement aux commentaires où la parade fut d'installer des capcha (vous savez les trucs illisibles à décoder qui rejettent votre commentaire trois fois sur quatre et qui parient sur l'insistance du lecteur), aucun test de Turing [NB2] ne pouvait fonctionner sur cette interface dont le principe est que justement deux machines parlent entre elles.
Nous en sommes arrivés là parce que certains font de la publicité, c'est à dire qu'ils touchent gratuitement du fric en vous polluant, se croient la raison d'être d'Internet, et créent des techniques purement maffieuses (et ça existe aussi en France !) allant du piratage jusqu'à l'extorsion de fonds...
Lors du redesign de mon site, j'ai profité du complet changement d'infrastructure pour passer à la nouvelle génération du moteur de ma blog zone. Aka Dotclear2. Et j'ai rouvert mes rétroliens, si longtemps maintenus en position fermés.
J'ai tenu trois semaines.
J'ai dû à regret à nouveau les fermer. Dommage, car faisant de la chronique de BD sur ce blog, ils permettaient de rapidement lier deux chroniques d'une même série ou d'un même auteur . Ou aussi d'écrire des articles à rallonge avec plein de liens vers de précédents billets, et de rétrolier ceux-ci.
Par contre, je dois reconnaître que Dotclear2 a une excellent suite de filtres sur les commentaires, qui ne laisse une chance qu'aux spammeurs manuels. Aucun faux négatif, mais hélas quelques faux positifs. C'est l'existence de ces derniers qui m'empêchent de laisser inonder la corbeille de récupération par d'innombrables rétroliens pollueurs.
On se souvient toujours de son premier cadavre
Il y a 48h, en surveillant mes logs Apache en direct [NB3], j'ai décrété que toutes les attaques de rétroliens étaient suffisamment calmés sur mon site pour tenter une petite expérience : j'ai intentionnellement rouvert [NB4] ce canal à spam, pour connaître comment ces salopards font leur marché.
Ça n'a pas duré, les robots maffieux ne respectent même pas les Dimanche après-midi. Voici la première trace gluante du retour des trackback-spams
Sa trace dans les logs Apache :
| IP | Date | Méthode | Adresse | User Agent |
| 64.202.165.201 | 7 Oct. à 15:55:28 | POST HTTP/1.0 | /blog.php/trackback/1156 | "TrackBack/1.02" |
Étonnement, le moteur Dc2 a vu autre chose :
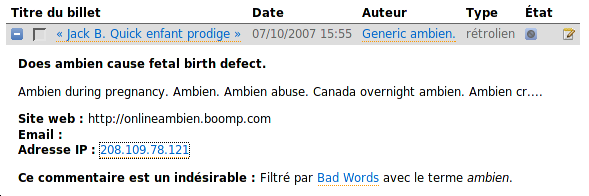
Je n'ai relevé aucun trafic IP dans mes logs Apache venant de l'adresse IP 208.109.78.121. On a donc une probable erreur propre à Dc2, ou à un spoofing quelconque d'IP. Visiblement, la DcTeam() à quelque chose à faire à cet endroit.
Passe passe passe le luminole
Intéressons-nous maintenant aux trafics menant à la page ciblée :
| IP | Date | User Agent déclaré |
| 208.68.136.5 | 30 Sept. à 17:56:21 | FAST MetaWeb Crawler (helpdesk at fastsearch dot com)" |
| 66.249.65.108 | 1er Oct. à 3:59:37 | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" |
| 74.6.24.19 | 1er Oct. à 16:07:06 | Mozilla/5.0 (compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp)" |
| 66.249.65.108 | 2 Oct. à 10:25:22 | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" |
| 66.249.65.108 | 3 Oct. à 13:40:48 | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" |
| 208.70.24.233 | 4 Oct. à 4:56:39 | Mozilla/5.0 (compatible; archive.org_bot/1.13.1x +http://crawler.archive.org)" |
| 74.6.24.143 | 4 Oct. à 12:29:13 | Mozilla/5.0 (compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp)" |
| 66.249.65.108 | 4 Oct. à 13:27:25 | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" |
| 24.68.74.198 | 4 Oct. à 23:27:08 | Mozilla/5.0 (compatible; SkreemRBot +http://skreemr.com)" |
| 66.249.65.108 | 5 Oct. à 21:57:31 | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" |
| 66.249.65.108 | 7 Oct. à 4:09:52 | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" |
Comme vous pouvez le constater, seuls des spiders [NB5] sont venus visiter cette page depuis la réouverture des rétroliens. Ce qui me permet d'arriver à ces déductions :
- Trop peu de gens s'intéressent à cet excellente BD qu'est « Jack B. Quick, enfant prodige », qui plus est très bien traduite par François Peneaud, confrère d'ActuaBD
- Trop peu de gens lisent mes chroniques BD, et encore moins mes archives de chroniques
- Les spammeurs utilisent exclusivement les moteurs de recherche, ou camouflent leurs spiders de manière à ce qu'ils semblent légitimes
- Les spammeurs utilisent des IRI de rétroliens récoltés depuis une belle lurette, et continuent à taper aveuglement dans ces adresses.
« Bon sang... Mais c'est bien sûr ! »
La moralité, c'est que les spammeurs ne perdent pas du temps à vérifier régulièrement la disponibilité de l'IRI de rétrolien d'un billet. Bien sûr, ils le font un minimum, d'où la diminution du trafic d'attaque qui met au moins un mois à décroître pour devenir quasi-nul.
À cet effet, je retenterais l'expérience dans un mois.
J'attends l'adaptation du plugin TrackbackTimeOut sur Dotclear2 (dans la génération Dc1.2, il y avait par exemple SpamTimeOut) pour les réactiver. Car dans mon étude (en fait, je m'y attendais), il se montre totalement pertinent : L'IRI de Trackback ne reste valable que pendant un temps limité, typiquement 5 minutes [NB6].
5 Minutes, le temps pour le Commissaire Raymond Souplex d'expliquer pourquoi Monsieur Michu est coupable. 5 minutes, c'est une éternité pour le programme de trackback légitime du blog “A” de signaler au blob “B“ que j'ai ici un billet qui a un rapport avec ton texte. 5 minutes, c'est un temps vraiment trop court entre deux visites de spider pour que l'IRI soit exploitable par un méchant vendeur de pharmacopée au service d'Al-Qaeda.
Et les messages pourris ne viennent pas encombrer la corbeille de récupération, celle où atterrissent parfois les messages de Thomas parce que quelqu'un utilise la même adresse IP que lui avec un MS-Windows totalement vérolé.
Nota Bene afin de faire semblant d'avoir tout compris à ce billet :
- ↑ IRI : IRI-ra bien, qui IRI ses URL... j'explique pourquoi ici
- ↑ test de Turing : Alan Turing est l'un des très grands théoriciens de l'informatique, hélas mort trop jeune. Le test qui porte son nom doit permettre de différencier si votre interlocuteur est un humain, ou une machine qui a le droit de mentir, tricher, se tromper,...
Tiens, en ce moment, vous pouvez tenter de savoir ce qu'un ordinateur pense du France/All Blacks d'hier soir, pour rire. - ↑ Lire les logs Apache : Pour des raisons de lisibilité, j'ai bien évidemment mis en forme ces logs cités dans ce billet pour que vous puissiez les comprendre. Le
tail -f access.logest typiquement un sport de geek, à peu près aussi palpitant que de compter les graines en suspension dans de la confiture de fraise maison. - ↑ intentionnellement rouvert : Les informaticiens appellent ça un “honeypot”, je préfère le terme policier de “dragnet”, parce que j'adore regarder cette série, et qu'on est effectivement dans un travail de planque, de filature et de serrage arme au poing.
- ↑ spiders : Les spiders, aussi appelés crawlers sont des bots conçus pour alimenter les moteurs de recherche.
Ces araignées cherchent les liens entre différentes pages, parcourant ainsi le web, la toile.
Dans mon tableau, on y voit celui de Google, de Yahoo, de Skeemr (un moteur de recherche de mp3), de FastSearch (une solution commerciale de recherche) et celui d'archive.org qui n'est pas un moteur de recherche, mais un archiveur. - ↑ 5 minutes : Techniquement, cela veut dire qu'il faut désactiver ou modifier dans Dc2 le moteur de cache de templates pour qu'une telle solution puisse marcher sans problème.
9 réactions
1 De Da Scritch - 07/10/2007, 18:28
À noter que pendant la rédaction de ce billet, les TB furent fermés, le bot a continué ses tentatives :
2 De da scritch net works - 07/10/2007, 22:38
Les spammeurs ont tué mes trackbacks
(Ceci est une démonstration de rétrolien : cette page parle d'elle-même !) Gloire et chute des rétroliens. Analyse d'une attaque de spams qui polluent un très bon outil de bloging....
3 De Da Scritch - 17/10/2007, 18:25
Je refais une tentative d'ouverture des TB. Hélas, toujours pas d'IRI jetable, mais j'essaie avec le plugin Rétro-Contrôle par Phénix.net http://www.xn--phnix-csa.net/spip.p... . Il n'accepte pas mes propres rétroliens, c'est le minimum que je lui demande.
4 De Sacha - 17/10/2007, 20:31
Bonjour Da Scritch,
L'option « Recherche récursive » est-elle bien activée au niveau de la configuration de Rétro-contrôle ?
Je vais faire des tests de mon côté car il se peut qu'il y ait effectivement un problème, en tout cas ça fonctionnait sur Dotclear 1. En attendant, pourquoi ne pas essayer Akismet ?
Concernant l'adresse IP, Dotclear n'enregistre pas toujours l'adresse IP réelle telle qu'elle est vue par un serveur Apache mais essaye de déterminer l'adresse qui se cache éventuellement derrière un serveur proxy. Cette méthode est à vérifier, je ne suis pas sûr qu'elle soit fiable.
5 De Da Scritch - 17/10/2007, 20:46
Bonjour Sacha, et merci d'avoir pis le temps de venir ici.
Askimet est déjà activé. La recherche récursive est activée, mais au cas où, j'ai white-listé l'adresse de mon serveur (en mettant le filtre IP en premier).
Maios mon principal souci est l'encombrement de la liste des indésirables, dans laquelle tombe parfois des messages légitimes. Je pense que le système d'IRI périssable est un excellent filtre pour les raisons expliqués plus haut.
La différence d'adresse pourrait être très intéressante à exploiter, en faisant la part des plages privées.
6 De e-t172 - 31/10/2007, 09:13
"Concernant l'adresse IP, Dotclear n'enregistre pas toujours l'adresse IP réelle telle qu'elle est vue par un serveur Apache mais essaye de déterminer l'adresse qui se cache éventuellement derrière un serveur proxy. Cette méthode est à vérifier, je ne suis pas sûr qu'elle soit fiable."
Elle ne l'est pas, c'est une erreur fréquente chez les développeurs PHP : cette fameuse méthode miraculeuse de "détéction de proxy" se fonde en réalité sur un en-tête HTTP falsifiable en 15 secondes montre en main. Du coup, si l'application est suffisamment mal codée pour ne prendre en compte que cet en-tête (en général il s'agit de l'en-tête non standard X-Forwarded-For), eh ben l'attaquant peut se faire passer pour n'importe quelle adresse IP. Pour éviter ça, une solution serait de conserver les deux adresses : l'origine réelle et le prétendu proxy. En effet, si on est sûr de pouvoir faire confiance à la première, en revanche ce n'est absolument pas le cas pour la deuxième.
7 De Sacha - 05/11/2007, 12:35
Je confirme ce que dit e-t172 : en ce moment-même, Da Scritch s'amuse à regarder l'IP de mon commentaire et il s'aperçoit que je m'appelle Google :p
8 De Da Scritch - 07/11/2007, 12:41
D'ailleurs merci Sacha. Je viens de mettre les TB jetables que tu as codé.
9 De Artis - 18/11/2007, 03:02
Intéressent tout ça. =-]
Sinon on peut poser des mines ?
Hein quoi ? Ah. Bon je sors... --->[]