

 Ce billet fait partie de la série en <img /> :
Ce billet fait partie de la série en <img /> :
- Histoires en <img />
- Manuel en <img />
- Ressources en <img />
- Bricolages en <img />
- Progressivement en <img />
- Finesse en <img />
- Propositions en <img /> / English version
Dites-moi, les jeunes, quelle est la vitesse de votre débit ? 12 Mbds ? 20 Mbds ? 500 Mbds ? Eh bien dites vous qu'il fut une époque où la vitesse moyenne de téléchargement plafonnait à 4,8 kbds ! À cette vitesse, cela voulait dire qu'un document de 100 ko mettait au mieux plus de 3 p☠♝☈➿ns de minutes à arriver en entier !
Internet, n'a pas toujours connu le haut-débit.
Des fois, les images sont chargées trop lentement alors on tente de les afficher prématurément. D'autres fois, on retarde exprès son chargement.
Ce dernier comportement peut se justifier, mais comporte de multiples erreurs.
Les images à chargement progressif
Donc, lors de sa préhistoire, le web n'arrivait à des débits de 1 Mbds que dans certains laboratoires, c'est à dire à moins de 10 mètres du serveur. La plupart du temps, quand on chargeait une image, ça se passait comme ça :

Source : voir plus bas
Certains formats de fichiers ont été spécialement conçus pour être transmis et affichés progressivement. Dans ce cas, l'algorithme de compression de l'image ne peut être optimum, mais cela permet un meilleur confort côté utilisateur si son modem est très lent.
À la haute époque dinosauriale des BBS, les serveurs qui se contactaient en RTC (donc par téléphone avec des modems qui allaient de 300 bauds à 4 kbds), un format a émergé en 1987, le GIF.
Le format GIF avait donc à la fois un excellent format de compression d'image pour l'époque (LZW) et un mode progressif d'affichage de l'image. Son principe était simple : au lieu d'enregistrer chaque ligne horizontale l'une après l'autre, on enregistre chaque ligne en en sautant 8, arrivé en bas de l'image, on repart du haut en prenant la ligne non-enregistrée suivante avec un pas deux fois plus fin. C'est un format entrelacé, dans un concept plus évolué que la télévision analogique qui alternait les lignes paires et impaires. L'idée étant de permettre d'avoir un aperçu (certes très pixelisé) global de l'image avant qu'elle ne soit complètement chargée.
Comme l'image ainsi enregistrée était plus lourde, eh bien on attendait moins longtemps. Logique.
Pour les logiciels clients qui pouvaient le gérer, nous obtenions un effet de stores vénitiens qui s'ouvraient progressivement. L'image complète se reconstituait en 4 “passes”.

Source : Dominique Toussaint sur Wikimedia
{kind=link}
À noter que le PNG possède aussi un mode entrelacé, un algorithme appelé “Adam7”, pour 7 passes :

Ce qui, dans les faits, donne un effet de mosaïque inverse :

Le format JPEG n'était pas prévu pour être un format de transmission bas débit, mais une fois qu'il fut supporté dans Netscape 1, il fut lui aussi doté d'un mode d'enregistrement progressif. Ce dernier tire parti du mode de compression par macroblocs, suivi d'un affinage par vaguelettes. Mais là encore, il se paie : le poids du document est sensiblement plus lourd.

Source : l'excellent article de Stoyan Stefanov sur le YUI-blog
Comme j'en ai déjà parlé dans un précédent chapitre de ce dossier, il se trouve que MSIE n'a jamais pris en compte l'affichage progressif d'une image. Et comme MSIE était devenu le navigateur dominant de l'ère proto-ADSL, enregistrer une image en mode progressif était devenu complètement contre-productif.
Cette solution du chargement progressif des images fut traité très différemment dans le cadre du son et de la vidéo, puisque lesdits types de documents sont techniquement conçus pour un décodage à la volée des données, au fur et à mesure de la temporalité du document, avec parfois une capacité à s'adapter à la vélocité de la transmission.
Vous ne m'avez pas compris ? Raaaah flûte !
L'attribut lowsrc=""
Une autre solution fut proposée par les constructeurs de navigateurs, l'attribut lowsrc="". Oui, j'en ai déjà parlé dans le deuxième volet, mais il mérite d'être mieux expliqué ici.
Donc, je vous en rappelle le principe, une image est appelée comme suit :
<img lowsrc="preview.gif" src="image.jpg">
L'idée étant que le navigateur commence par charger preview.gif qui est une version monochrome de l'image normale et donc largement plus rapide à télécharger, une ombre théoriquement fugace qui ne persiste que les 4 minutes nécessaires pour récupérer tout les autres éléments de la page.
Cela demande forcément de traiter en avance l'image, puisque dans les années 1990s, vous n'aviez pratiquement pas de solution pour éditer une image côté serveur.
Si je reprends l'image du dessus, ça donne ça :

À noter que l'apparition progressive de l'image pouvait avoir lieu selon certaines conditions passant de vaudou
à black magic
jusqu'au fatidique en fait, non, arrête : ça ne sert strictement à rien
…
La troisième capture simulée n'est pas complète ?
Eh ben oui, forcément, comme il faut charger deux fois l'image, ça prend largement plus de temps pour l'afficher proprement au final. Or c'est justement cette double négociation qui peut prendre le plus de temps dans certains cas. Finalement, cet attribut a plus ralenti les navigateurs que donner une impression de rendu accéléré
, il s'est montré contre-productif. lowsrc="" n'a d'ailleurs jamais été standardisé par le W3C, et a disparu dans les cendres d'une époque pré-CSS. Il a été oublié par tous les navigateurs qui l'avaient implémentés, à ma connaissance, Netscape, Opera et quelques navigateurs embarqués dans des feature phones.
Sauf quelque SEO-LOL qui me soutenait mordicus qu'il faut déclarer deux fois la même ressource <img lowsrc="image.jpg" src="image.jpg"> parce que « Ça donne plus d'importance à l'image pour les moteurs de recherche ». Si ! Si ! Il y croyait fermement. Facepalm dans sa tronche.
Lazy loading : Le chargement volontairement différé
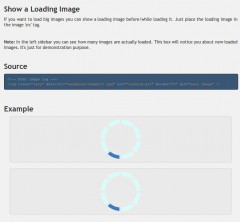 Le lazy loading est une “mode” apparue en 2010. Elle consiste à ne pas laisser les navigateurs charger naturellement les images, mais attendre que l'endroit où l'image doit apparaître soit visible dans le viewport. Ce comportement est réalisé par une bibliothèque javascript. Une idée qui fonctionne pour les pages web qui ont une certaine longueur.
Le lazy loading est une “mode” apparue en 2010. Elle consiste à ne pas laisser les navigateurs charger naturellement les images, mais attendre que l'endroit où l'image doit apparaître soit visible dans le viewport. Ce comportement est réalisé par une bibliothèque javascript. Une idée qui fonctionne pour les pages web qui ont une certaine longueur.
Attention : nous ne sommes pas dans le concept de scroll infini, où des portions complètes de contenus sont chargées au fur et à mesure qu'on descend dans la page. Ici, l'ensemble du texte, du layout, du DOM, des éléments du document sont chargées, SAUF les images, et donc il faut descendre pour que le chargement se déclenche.
Sincèrement, je trouve ce système extrêmement désagréable. Je prends par exemple un article que je commence à lire. Au bout d'une minute, souhaitant lire la suite, je scrolle avec ⇟ Page down, des espaces blancs apparaissent brusquement dans le texte, puis des images arrivent. Cela distrait le lecteur, et donne une forte impression de lenteur au site. T'avais pas le temps de tout charger alors que je lisais tes premiers paragraphes ? SRSLY
Source : pool flickr de Sud Web 2014
Pourquoi Dirty Hacky va dégainer et tirer sans sommations ? Parce que la sémantique html de votre page est cassée, elle perd de son sens. Un peu comme si je mettais une passoire à un endroit, et que si je la regarde, au bout de 3 secondes, une casserole apparaît à sa place.
Les navigateurs chargent toutes les ressources sans chercher à voir s'il y en a immédiatement besoin. Oui, bravo, tu viens de définir exactement le principe d'intégrité d'un document. Mais peut-être ne sais-tu pas que le web est utilisé bien au-delà de ton navigateur web ?
Forcément, ignorer la sémantique casse beaucoup de fonctions normales du web :
- Si votre javascript ne se charge pas ou plante brusquement, les images n'apparaissent absolument pas ;
- L'indexation de votre page par les moteurs de recherches risque de devenir incohérente voire fortement pénalisée ;
- L'indexation des images par ces mêmes moteurs ne se fait plus ;
- Cela gâche l'impression d'une page, puisque les images ne sont pas chargées par défaut, il faut faire défiler entièrement la page dans son navigateur avant, et encore… ;
- En cassant le web sémantique, on casse aussi l'usage de services tiers comme les flux RSS, ou encore les lecteurs différés comme Wallabag ou Pocket puisque les images n'y apparaîtront jamais ;
- Les avantages à venir des navigateurs, notamment un éventuel chargement intelligent des ressources selon leur position géométrique, ne sera jamais exploitable ;
Je me suis rendu compte que la plupart des sites qui utilisent de genre d'artifice ont du texte au kilomètre, suivi d'un nombre très conséquent d'images, le tout préfixé par un titre dans le genre « Les 500 images de clowns se cassant la gueule qui font rire » ce qui leur assure un fort trafic.
Après avoir longuement tortionné à l'épluche-légume une des personnes qui l'utilise (Oui, l'épluche-légume m'a semblé être l'outil le plus à même de faire comprendre la torture induite par ce genre de script à la con), j'ai enfin eu des raisons “valables” :
- « Parce que j'ai une page trop lourde donc elle met trop de temps à se charger. » Déjà, enlève 50% de tes javascripts de pubs, tasse tes assets, optimise la compression de tes images et surtout simplifie au maximum ta maquette : elle est sûrement trop complexe ;
- « Parce que mon serveur a beaucoup trop de traffic à encaisser. » Alors commence à investir dans un serveur auxiliaire, fait appel à un vrai CDN, voire commence à faire du load balancing au cas où ton serveur crashe ;
- « Parce que je me fais sans cesse piquer mes images. » C'est le principe du web, même si tu bloques l'accès à “Voir le code source” ou à "Enregistrer l'image sous" par le menu contextuel, tu n'as aucune chance d'empêcher ni le Ctrl+U, ni le F12. Alors un
wgetdes familles, n'en parlons pas. Peine perdue ; - Et enfin ce p'tit con qui est trop jeune pour avoir eu un modem 28kb de chez US Robotics, il me dit que « mais c'est trop génial, ça donne un effet totalement inédit… ».
 C'est à ce moment-là qu'il a perdu d'une manière inédite ses dernières dents, dommage collatéral à cette enquête de terrain par votre serviteur. Dirty Hacky conclu l'interrogatoire avec sa phrase habituelle :
C'est à ce moment-là qu'il a perdu d'une manière inédite ses dernières dents, dommage collatéral à cette enquête de terrain par votre serviteur. Dirty Hacky conclu l'interrogatoire avec sa phrase habituelle :
BANG ! BANG ! BANG !
Le chargement avec… une iframe ?!?
Ça, c'est tout récent, et c'est surtout le fait de Getty Images. Getty Images comporte le plus important fonds de photos historiques et un des plus importants en images d'illustrations, ce qu'on appelle improprement le libre de droit
. En temps normal, l'usage de ce trésor est loué à prix d'or aux professionnels et l'achat d'art
est un poste souvent négligé par des web-agencies d'amateurs. Getty a d'ailleurs une réputation agressive à pousser son copyright parfois très loin.
Depuis Mars dernier, Getty Images met gracieusement à disposition des blogueurs une partie de son catalogue d'image, mais avec d'importantes contreparties. Notamment l'insertion doit être fait avec <iframe></>. Avantage : le design est conservé, les crédits de l'image aussi et l'agence peut parfaitement tracer l'usage et l'audience de son catalogue. Et, oui, nous avons bien un chargement différé de ce contenu par rapport au reste du document, puisqu'une iframe est souvent chargé en tout dernier par rapport aux autres assets de la page.
Pour embarquer l'image précédente, voici le code source totalement overkill que Getty Image me propose d'insérer :
<div style="[…]">
<div style="[…]">
<iframe src="//embed.gettyimages.com/embed/79989152?[…]" width="594" height="482" scrolling="no" frameborder="0" style="[…]"></iframe>
</div>
<p style="[…]"></p>
<div style="[…]"><a href="http://www.gettyimages.com/detail/79989152" target="_blank" style="[…]">#79989152</a> / <a href="http://www.gettyimages.com" target="_blank" style="[…]">gettyimages.com</a></div>
</div>
Je me demande si je n'aurais pas dû prendre comme illustration l'image d'un garçon présentant une obésité morbide…
Là, c'est même pas moi qui va m'énerver, mais les constructeurs de navigateurs web, car une insertion d'<iframe></> est loin d'être gratuite en terme de consommation mémoire ; j'ai rapidement abordé ce sujet à propos des boutons de partage sur les réseaux sociaux. Alors imaginez quand une page en comporte une cinquantaine… L'abus d' <iframe></> est actuellement l'une des principales causes de crash de navigateurs.
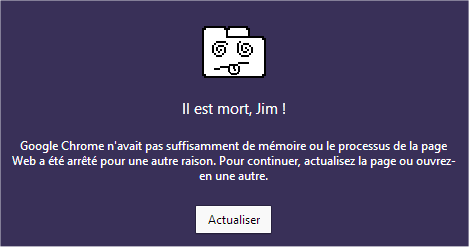
Source de la capture : astucehebdo
Bientôt la fin ?
Dans le chapitre suivant, je parlerai enfin du problème qui m'a motivé à écrire ce dossier : le problème de l'affichage d'une image en fonction de la résolution de son support. Vous verrez qu'on va parler à la fois des formats ésotériques, d'un retour du lazy-loading et ce d'une proposition que Daniel ne peut pas refuser…
7 réactions
1 De Frédéric Kayser - 11/06/2014, 04:42
Je me sens obliger de corriger légèrement l’article surtout concernant la partie affichage entrelacé et progressif.
Pour commencer l’explication de l’entrelacement du gif est légèrement fausse ou pas claire.
Si dans un gif non-entrelacé les lignes qui constuent l’image sont enregistrées dans l’ordre 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15, dans un gif entrelacé on aurait (0,8) (4,12) (2,6,10,14) (1,3,5,7,9,11,13,15), les parenthèses matérialisent les 4 passes successives. Une façon mathématique de voir la chose est de mettre dans la première passe les lignes qui sont multiples de 8, dans la deuxième les multiples de 4 (mais sans les multiples de 8 qu’on déjà transmis), dans la troisième les multiples de 2 (mais sans les multiples de 4 et 8) et dans la dernière passe ce qui reste (les lignes impaires en fait).
En suite et c’est le point sur lequel je tiens vraiment à corriger l’article, une image entrelacée ou progressive ne produit pas nécessairement un fichier plus gros. Il faut toutefois tenir compte du format d’image utilisé si l’on veut essayer de généraliser.
PNG) Oui, les images entrelacées occupent généralement plus de place dans le fichier, c’est même pratiquement toujours le cas (sauf cas clinique).
GIF) Ça fait un moment que je n’ai pas tenté l’expérience, mais l’entrelacement ne nuit pas nécessairement à la compression, le logiciel d’optimisation ImageOptim dont la réputation n’est plus à faire sur OS X réalise d‘ailleurs deux appels distincts à gifsicle, une fois sans entrelacement et une fois avec (cf. https://github.com/pornel/ImageOpti...) :
} else if (fileType == FILETYPE_GIF) {
if ([defs boolForKey:@"GifsicleEnabled"]) {
GifsicleWorker *w = [[GifsicleWorker alloc] initWithFile:self];
w.interlace = NO;
[runLater addObject:w];
w = [[GifsicleWorker alloc] initWithFile:self];
w.interlace = YES;
[runLater addObject:w];
}
JPEG) Là clairement non, un enregistrement progressif ne sera que rarement plus gros.
Il faut bien comprendre qu’un JPEG séquentiel et un JPEG progressif contiennent exactement les mêmes informations, il n’y a pas de données supplémentaires ajoutées pour réaliser l’effet progressif. En fait tout ce qui change est l’ordre dans lequel on transmet les informations :
Dans un JPEG séquentiel chaque "data-unit" (en gros une matrice de 8x8 contenant un coefficient DC et 63 coefficients AC) est transmis intégralement, les data-units sont regroupés en MCU (ou macro-block), chaque MCU permet de reconstituer une petite surface de l’image souvent 8x8, 16x8 ou 16x16 pixels (c’est lié au sous-échantillonnage chroma) et contient donc généralement tous les composants « couleur ». Comme le JFIF fonctionne dans un espace YCbCr (et non RVB comme on le croit parfois), sans sous-échantillonnage chroma un MCU contient un data-unit pour le composant Y et de même pour Cb et Cr donc 3 data-units en tout, avec un sous-échantillonnage chroma de type 4:2:0 un MCU contient 4 data-units pour le composant Y, et un data-unit pour Cb et Cr donc 6 data-units en tout (ce qui permet de reconstruire un carré de 16x16 pixels, contre 8x8 précédemment). Dans le fichier les MCU se suivent et décrivent l’image de gauche à droite et de haut en bas.
Dans un JPEG progressif on va fractionner les data-units en regroupant des coefficients semblables dans différentes passes (ou scans), la première passe contient nécessairement le coefficient AC seul, très souvent on regroupe les trois composants dans cette passe*, celle-ci contient donc en gros 1/64ème des données de l’image. Après le format JPEG offre une liberté énorme pour transmettre le reste de coefficients, il n’y pratiquement que deux contraintes, une passe ne peut désormais plus que contenir un seul composant (Y ou Cb ou Cr), si plusieurs coefficients sont envoyés ils doivent se suivre le long du chemin en zig-zag qui décrit la matrice de 8x8. On peut donc imaginer des centaines voire des milliers de façons différentes d’envoyer le reste des données, les deux extrêmes étant :
- 3 passes (une pour Y, une pour Cb et une pour Cr) avec à chaque fois la totalité des coefficients AC (avec la première passe pour DC, on a donc un minimum de 4 passes)
- 189 passes (63 pour Y, 63 pour Cb et 63 pour Cr) avec dans chacune un seul coefficient AC.
Mais ce n’est pas tout, ce que je viens de décrire est juste l’approche « spectrale » de l’enregistrement progressif, car il est également possible de ne pas envoyer la totalité d’un coefficient, mais juste une fraction de celui-ci (les bits les plus forts), le reste (les bits les plus faibles) seront envoyés dans des passes ultérieures… et nécessairement un seul à la fois. Ceci constitue l’aspect « raffinement progressif ».
Je me doute bien qu’à ce point vous êtes très probablement complètement largués surtout sans illustrations… Maintenant pourquoi une image progressive prendrait-elle en définitive moins de place, en fait lorsqu’on émet juste quelques coefficients qui se suivent il y a un peu plus de chances pour qu’ils soient semblable (si ce n’est en valeur au moins en grandeur) et l’étape suivante de la compression (la réduction de l’entropie) va un peu mieux fonctionner dans ce cas, en gros en cassant les data-units en différents groupes de coefficients, on associe ces derniers à leurs semblables et ce regroupement facilite légèrement la compression.
C’est pourquoi des scripts comme JPEGrescan tentent quelques dizaines de façons différentes de produire un JPEG progressif et gardent la méthode qui produit le plus résultat pour un fichier donné (désormais mozjpeg fait ça tout seul).
Ce qui c’est passé historiquement (et c’est un peu triste), les spécifications JPEG n’étaient pas encore finalisées et publiées mais l’attente vis-à-vis de ce format était telle que diverses implémentations ont commencées à fleurir dès le début des années 90, comme les specs ne définissaient pas à proprement parler un format de fichier et étaient totalement agnostiques vis-à-vis des espaces colorimétriques C-Cube a proposé un format d’échange : le JFIF qui est rapidement devenu un standard de fait et qui est officiellement devenu la partie 5 des spécifications JPEG en… 2013. Le format connait donc un succès fulgurant aidé par l’apparition d’une bibliothèque libre (libjpeg d’IJG) permettant de décoder et d’encoder des images JPEG, au début seul le JPEG séquentiel et même de manière encore plus restrictive le JPEG "baseline" est supporté, comme l’article l’a expliqué la lenteur des moyens de communication numérique de l’époque poussent à l’adoption du JPEG progressif (ce dernier étant largement plus complexe il a fallu un peu plus de temps pour disposer d’en/décodeurs pleinement inter-opérables*), donc en quelques années un boom énorme se produit des images par millions, plein de logiciels qui se proclament à même de gérer du JPEG (et une énorme majorité à l’aide la libjpeg d’IJG)… mais à vrai dire, à ce point, on a juste un tiers des spécifications qui sont réellement exploitées; si vous lisez les specs un jour (c’est un gros pavé tout de même, aujourd’hui il est gratuit ça aide… car au début c’était payant) vous remarquerez que certains chapitres vont vous sembler très étranges car on ne croise pas souvent de JPEG dotés de :
- la compression sans perte de données (ce n’est pas une grande perte, c’était pas terrible et désavoué par JPEG-LS -un cousin assez éloigné du JPEG pur jus- et JPEG-XT… le petit nouveau de cette année)
- une profondeur de 12-bits par composant (des images HDR)
- l’encodage arithmétique (des fichiers 7% plus petit, mais protégé par des brevets d’IBM qui sont tombés depuis, la libjpeg version 7 permet de l’utiliser)
- l’enregistrement hiérarchique (des images dont la définition ou la résolution augmentent progressivement d’un facteur deux, un seul fichier peut par exemple contenir la même image en 320x200, 640x400 et 1280x800 chaque taille reposant sur les données de la précédente pour ne pas prendre trop de place, un truc jugé inutile il y a une quinzaine d’années…)
Aujourd’hui il est malheureusement trop tard pour espérer rajouter tout ça vu les incompatibilités que cela provoquerait ; mais au moins vous ne serez plus dupe : aucun logiciel ne supporte pleinement le JPEG. Il y a peut-être un effet pervers lié au succès et la situation de quasi monopole de la libjpeg (et dérivés -turbo) qui fait très bien ce qu’elle fait, mais ce qu’elle fait ne couvre malheureusement pas la totalité des spécifications.
* En fait on arrive toujours pas décoder universellement du JPEG, essayez d’ouvrir cette image dans Adobe Photoshop : http://frdx.free.fr/champilampe-kil... (illustration de ce qui se passe si l’on ne met pas les trois composants dans la première passe d’un JPEG progressif)
Petite démo relative de la taille inférieure des JPEG progressifs.
Image séquentielle :
http://frdx.free.fr/champilampe-seq...
16567 octets
Image progressive (produite à partir de la précédente avec jpegtran -progressive) :
http://frdx.free.fr/champilampe-pro...
16193 octets
Image progressive optimisée par mozjpeg (jpegtran -mais celui de mozjpeg-) :
http://frdx.free.fr/champilampe-moz...
16160 octets
Si vous êtes super curieux vous pouvez analyser les différentes passes des images précédentes avec JSK (JPEG Scan Killer) et également trouver quelques illustrations liées à l’encodage JPEG ici :
http://encode.ru/threads/1800-JSK-J...
Et par pitié ne pas parler de vaguelettes concernant JPEG car c’est un concept propre à JPEG2000, JPEG repose sur la DCT (Transformée en Cosinus Discrète) qui permet de passer d’une représentation spatiale (des pixels en 2D) à une représentation spectrale (des coefficients), la transformation inverse produisant… l’inverse et si l’on a un peu raboté les coefficients entre temps l’image sera peut-être qu’un peu déformée, mais si ça se trouve les coefficients rabotés sont assez facile à stocker sous forme compressée… et on peut peut-être régler la profondeur du coup de rabot pour en faire un paramètre de qualité permettant de choisir entre une image relativement fidèle mais lourde et une image altérée mais plus légère, c’est fou ce truc !
2 De Da Scritch - 11/06/2014, 07:39
Hello Frédéric,
C'est un plaisir de se faire "corriger" par vous car vos interventions sont toujours fort à propos
J'avoue que j'ai pas repris mes tests faits en 2003, mais à l'époque, le gain de poids oscillait entre 5% et 20% sur un Photoshop 5.5.
Pour ce qui est des vaguelettes plutôt que du cosinus discret, je plaide coupable : la blague à base de vaguelettes est plus facile
3 De Boris - 18/06/2014, 07:52
Relecture : "sauf quelque SEO-Lol..." il manque le pluriel à quelques et la conjugaison qui va avec.
4 De Boris - 18/06/2014, 08:24
Je ne sais pas si mon premier commentaire est passé, il y a une faute dans "Sauf quelque SEO-LOL qui me soutenait" <= il manque le pluriel à "quelque" et "soutenait". Ou alors il n'y en avais qu'un :) ?
5 De Da Scritch - 18/06/2014, 08:30
Y'en avait qu'un. Je ne cautionne pas le meurtre de masse.
6 De Boris - 18/06/2014, 08:35
1) Merci pour tes articles, c'est très intéressant et agréable à lire
2) Merci Frédéroc, j'ai aussi appris plein de choses dans ton commentaire
3) Quelques petites réflexions sur ce que j'ai pu lire ci-dessus sur le LazyLoading :
"Si votre javascript ne se charge pas ou plante brusquement, les images n'apparaissent absolument pas"
Contre le plantage du JS, point de salut car il n'y a pas vraiment de reprise sur incident. En revanche, il est très possible d'utiliser la balise <noscript> pour avoir une image en fallback en cas de désactivation de JavaScript.
"L'indexation des images par ces mêmes moteurs ne se fait plus ;"
Encore une fois, l'usage d'une balise <noscript> peut compenser ce problème.
"Cela gâche l'impression d'une page, puisque les images ne sont pas chargées par défaut, il faut faire défiler entièrement la page dans son navigateur avant, et encore… ;"
Tout dépend comment les images sont chargés, elles peuvent être pré-chargées en suivant une certaine distance par rapport au viewport (par exemple, 300px sous la ligne de flottaison). Si tu ne scrolles pas comme un grand malade de l'index, ça devrait faire l'affaire.
"En cassant le web sémantique, on casse aussi l'usage de services tiers comme les flux RSS, ou encore les lecteurs différés comme Wallabag ou Pocket puisque les images n'y apparaîtront jamais ;"
<noscript> !
"Je me suis rendu compte que la plupart des sites qui utilisent de genre d'artifice ont du texte au kilomètre, suivi d'un nombre très conséquent d'images, le tout préfixé par un titre dans le genre « Les 500 images de clowns se cassant la gueule qui font rire » ce qui leur assure un fort trafic."
Non, tu as aussi un véritable besoin de LazyLoading dans les vitrines e-commerce qui affichent plusieurs dizaines de produits en mosaïque sur une même page. On le trouve aussi de plus en plus dans les WebDoc, ces formats longs de la Presse en ligne.
"Déjà, enlève 50% de tes javascripts de pubs, tasse tes assets, optimise la compression de tes images"
Et si mon business model repose sur la pub, que le reste est déjà fait et que quand je simplifie ma maquette, la transformation e-commerce est moins bonne. Cas vécu, validé et testé ;)
Bon allez, si ça se trouve, tu dis tout ça dans la suite !
7 De Da Scritch - 18/06/2014, 08:38
Boris, tu spoiles le chapitre suivant sans le savoir ;)