


Ce billet fait partie de la série  des emoji dans l'Unicode et a été proposé comme sujet candidat à Sud-Web 2012 :
des emoji dans l'Unicode et a été proposé comme sujet candidat à Sud-Web 2012 :
 Ces smilies chatoyants
Ces smilies chatoyants L'alphabet visuel des keitai
L'alphabet visuel des keitai Techniquement si séduisants
Techniquement si séduisants Chacun a sa manière
Chacun a sa manière Leçons pour le webdesign
Leçons pour le webdesign
 Présentation en live
Présentation en liveAllez, dernier épisode. TL;DR ? Sautez directement aux conclusions et apprenez par cœur la leçon. J'en parle ce soir lors de l'Apéro Web chez Occi-tech. Et y'en a des choses à découvrir.
Dissymétrie des systèmes
Vous avez vu que trois opérateurs ne veut pas dire 3 mais bien 12 manières différentes d'appeler (quasiment) le même emoji. Tant que les téléphones ne marchaient que sur l'archipel et ne pouvaient changer de réseau, on faisait avec. Mais quand Apple a voulu vendre ses iPhone au pays des feature phones, les gaijin venus de Cupertino ont dû sentir des sueurs froides quand les opérateurs leur ont parlé d'emoji. Dans la pièce à côté, l'équipe commerciale venait enfin de convaincre leur partenaire qu'ils n'avaient pas besoin de créer une mascotte pour promouvoir l'iPhone.
Apple était obligé d'inclure les emoji sur ses iPhone pour pouvoir les vendre au Japon : Le public est archi-demandeur.
Ils furent donc inclus lors du lancement de l'iPhone au Japon, mais, pour des raisons à la fois de copyright et du manque de standardisation, uniquement accessible pour les clients SoftBank (l'opérateur nippon qui a eu l'exclu du bestiau).
Le système d'exploitation iOS étant censé uniforme pour l'ensemble des portables de la gamme, ces emoji étaient donc présents, mais inaccessible sur les autres locales. À moins de connaître la commande magique.
Mais comme en France, le tabou de l'opérateur exclusif venait de péter, Apple préparait déjà une distribution sans exclusivité nationale. Or, on l'a vu dans le tableau, chaque opérateur Japonais avait sa méthode d'appel incompatible. De son côté, Google commençait à proposer son système Android, directement concurrent d'Apple. Sauf qu'Android est thémable, ce qui permettait aux opérateurs/fabricants de créer des keitai très… très, quoi.
Les deux concurrents en venaient à la même conclusion : il était sage de ne froisser personne, et de faire des réunions de conciliation via le consortium unicode. C'est ainsi qu'Apple et Google ont travaillé de concert afin de standardiser les emoji.
C'est une spécificité du monde des affaires au Japon : on peut réunir 5 sociétés dans la même pièce qui ont tout pour s'étriper, et que personne n'en ressorte mécontent.
À moins que l'envie d'avoir un iPhone…
Unification (nan, ça n'est pas un cri de guerre de super-sentaï)
C'est ainsi qu'a commencé un travail de titan :
Autour de la table, tout le monde est d'accord, internet doit être unifié, l'unicode est l'avenir. Fini les charsets un peu bizarre genre Shift_JIS, les bricolages à plans alternatifs, les balises étranges et les attributs XML bizarroïdes référencés dans aucune DTD, les références à des éléments ROM embarqués propriétaires, etc…
HTML5 et unicode, purs et standards. Enfin.
Il a été vite convenu qu'aucun point d'appel propriétaire d'un opérateur ne sera standard. Surtout ceux qui utilisent des points CJK standardisés, et on libère les plans à usage interne. On repart de zéro, tout le monde perd la face, donc tout le monde est prêt à discuter. On raccroche aux symboles déjà existants si c'est possible. Pour les autres, il ne reste de la place qu'après U+10000, mais on est en 2012, donc cela pose beaucoup moins de problèmes qu'avant d'indexer les caractères au-delà de 2¹⁶.
Malgré tout, la tablée a dû convenir que certains glyphes ne pouvaient pas être dédoublonnés, à cause de l'usage. Par exemple, il existe déjà en unicode un symbole pour les établissement bancaires. Alors pourquoi ajouté les deux versions emoji ? Comme on l'a plusieurs fois dit, les Japonais sont friands de jeux de mots plus ou moins obtus. Le symbole des banques est en général symbolisés sur les keitai par les lettres BK (exemples : 
 ). À l'usage, les Japonais ont utilisé cet emoji sur les e-mails/bbs/forums, mais pour une tout autre signification : « Baka ! » (« Débile ! »). Comme le symbole unicode des banques n'a pas forcément ces deux lettres, il était important de recréer ces symboles, U+26FB ⛻️.
). À l'usage, les Japonais ont utilisé cet emoji sur les e-mails/bbs/forums, mais pour une tout autre signification : « Baka ! » (« Débile ! »). Comme le symbole unicode des banques n'a pas forcément ces deux lettres, il était important de recréer ces symboles, U+26FB ⛻️.
|
Tableau de démonstration des variances caractères extrait du site du Consortium Unicode |
||
| 26FA FE0E | 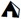 |
TENT text style |
| 26FA FE0F |  |
TENT emoji style |
| 26FD FE0E | 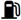 |
FUEL PUMP text style |
| 26FD FE0F |  |
FUEL PUMP emoji style |
Ainsi, le café ☕ U+2615 peut prendre des couleurs si on ajoute le caractère (invisible) ☕️ U+FE0F, ce qui donnerait le code html
☕️. Astuce qui ne pose pas de problèmes pour les systèmes ne le supportant pas.
Les opérateurs furent d'accord pour “libérer” le jeu des emoji, puisque certains sont des designs industriels protégés. Mais comme pratiquement tous les emoji ont été clonés entre opérateurs, ce n'était qu'acter ce qui se faisait déjà.
Nouveaux caractères surprises
Parmi les nouveaux groupes de caractères, on note l'arrivée de binettes d'animaux, principalement de chats et de chiens. Ben oui, on est dans le pays de la kawaii-attitude.
L'arrivée de nourriture, aussi, avec une très nette dominante asiatique (à partir de U+1F354). En Asie, ils sont peut-être plus obsédés que nous dans la représentation de la nourriture.
Autre arrivée, celle de bâtiments et enseignes, notamment les distributeurs bancaires, les hôpitaux, les hôtels et… les love hotels (si si ! U+1F3E9 🏩 qui va de pair avec l'archi-sexy sexiste symbole de la femme avec des oreilles de bunny (U+1F46F 👯, celui-ci, j'attends son entrée dans un iPhone ou dans Windows), mais pas avant d'avoir mis tous les nouveaux cœurs dans l'e-mail à votre partenaire (U+1F493 💓 à U+1F49F 💟, plus les versions emoji).
Perso, je n'oublierai pas U+1F4BD 💽 avec une larme émue. Tandis que les propagateurs de memes auront découvert le symbole officiel du  caca mignon. U+1F4A9 💩 « Pile of poo ».
caca mignon. U+1F4A9 💩 « Pile of poo ».
Tous ces caractères font désormais partie de la sarabande unicode, version 6.1, environ vers U+1F300,
soit dans ce film, 1h24mn :
vidéo par Decode Unicode hébergée chez Vimeo
Des erreurs que nous faisons encore
Cet article, même si son écriture a commencé en Avril 2009, est toujours d'une actualité brûlante.
Depuis l'arrivée des webfonts universelles (n'oublions pas que MsIE6 avait déjà une fonction équivalente), plusieurs webdesigners ont crû intelligent d'utiliser une police dingbats.
Erreur ! On abandonne complètement la sémantique originelle des symboles et des lettres. J'avais déjà parlé de la sémantique de certains caractères séparateurs de mots ou de syllabes.

Vous allez p'têt pas m'croire, mais y'a écrit 4 fois la même chozeuh.
Si une police gothique peut être lue, c'est qu'un « F » dessine un « F ».
Imaginez un site qui utilise des « J » , des « P » et des « 5 » disséminés... mais qui symbolisent un téléphone, une enveloppe ou une carte bancaire stylisée avec une police dingbat très précise.
Vous êtes alors lié à la présence de cette police, car aucun fallback ne pourra convenir : Un tel comportement n'a évidemment rien de standard, et donc aucune autre police dingbats convenir pour votre petite fantaisie de présentation.
Répétez ce mantra :
Une consonne est une consonne,
un chiffre, un chiffre,
une virgule, une virgule,
point.
Dans le cas où le navigateur n'arrive pas à charger la webfont, c'est un peu incompréhensible. Si on prend un navigateur web de type lecteur braille pour les aveugles, c'est carrément une idée stupide comme le dit poliment Raphaël Goetter. Et ça l'est d'autant plus si justement les symboles que vous comptiez utiliser ont déjà leur rond de serviette numéroté sur les plans de table de l'Unicode.
C'est justement pour éviter le cas de figure des documents Ms-Word (au hasard) remplis de fioritures avec des polices dingbats, (sans parler de ce genre d'aberration) que le Consortium Unicode a prévu plein de ces caractères fantaisies. Il y en a même un chapitre complet sur le sujet, en PDF, qui précise bien que les implémentations n'ont jamais valu des poursuites d'Hermann Zapf, fondeur de la police dingbat la plus connue. Sur plusieurs plans, vous retrouverez toutes les étoiles, boulets (arf!), symboles “universels” pour ne pas avoir à substituer un caractère significatif. C'est même encore mieux puisqu'il n'y a plus à prévoir la disponibilité d'une telle “police”, et qu'en cas de lecture de ce type de texte par exemple par une synthèse vocale, ben ces symboles du coup prennent une réelle signification.
Si vous désignez une police et que vous créez des glyphes spécifiques (l'exemple avec Font Awesome), utilisez toujours les adressages « usages privés » pour les installer. Ne faites jamais de substitution ! Et au mieux, essayez de voir si la description de votre glyphe ne correspond pas déjà à une entité Unicode existante.

Il existe d'excellents outils pour surfer sur l'unicode, installés de base dans tous les bureaux.
Ici, kcharselect , fourni par KDE4. Classé par thèmes, descriptifs complets, codes, très utile.
La bonne pratique ? il est plus intelligent d'utiliser les fameux emoji qui pourraient être interprétés. La sécurité étant de trouver bien évidemment une webfont universelle (jusqu'à MsIE 6) qui comporte dans ses symboles, lesdits emoji. Oui, je sais, il n'y a que 5 ans, il était très difficile de trouver une police fantaisie qui vous plaise avec toutes les lettres accentuées et le symbole euro…
Une des propriétés les plus intéressantes des bibliothèques d'affichage de texte utilisant les plans Unicode, c'est qu'en cas d'absence d'un pan particulier de caractères dans une police d'affichage, celle-ci est substituée par une autre police comportant le glyphe manquant. C'est pour ça que si une police ne comporte pas les lettres accentuées françaises, votre système d'exploitation va tenter de la remplacer par la même lettre issue d'une des polices génériques. Il vous est sûrement arrivé de trouver un “é” en Arial en plein milieu d'une si belle police cursive (si si, regardez le tableau plus haut). La plupart du temps, pour un symbole peut fréquent du type dingbats, c'est ce qui arrive.
À noter que le kit de développement pour l'Europe de sites i-mode comportait un document en “.tte”, soit une extension des polices TrueType.
Autre exemple : retour d'expérience avec les glyphes symboles
Pour une application à destination des télévisions connectées, j'avais proposé de remplacer l'usage des images et (presque) des emoji. La raison était simple : la set-top-box était susceptible d'avoir au moins 4 résolutions différentes (du NTSC au 1080), sans compter les variations de ratio (16:9, 16:10, 4:3,…). Même si je ne suis nullement web-designer, j'avais prévu bien en amont d'utiliser des dimensions relatives.
J'avais donc proposé d'utiliser ◀◀ ▮▮ ▶ ⬛ ▶▶, des glyphes présents depuis près d'une décennie dans le thesaurus unicode. ce qui facilitait grandement les animations d'interactions qu'on allait pas tarder à me demander, mais surtout évitait un abscons labeur d'adaptation graphique pour des éléments de décor triviaux. Comme je l'ai dit, je suis un piètre web-designer.
Et avouez que ça a de la gueule :
◀◀ ▮▮ ▶ ⬛ ▶▶
Enfer et damnation, la box en question, pourtant conçue par un très grand du web et utilisant une police très présente sur les distributions Linux, ne disposait pas des susnommés caractères unicodes. Sa version de police embarquée datait de plus de 2 ans, alors que la box était sorti 2 mois plus tôt.
Elle y affichait en lieu et place les fallbacks, comme précédemment décrit : du ▯ là où on attendait des jolis symboles de magnétoscope.
P▯▯▯▯n de b▯▯▯▯l de m▯▯▯e, il a fallut remettre en cata des images, dans les au moins sets de 4 dimensions prévus.
Et les ratios.
Et les scopes.
N'oubliez pas
Ces règles devraient être enseignées au burin depuis l'arrivée de l'unicode :
- Un caractère est l'élément le moins accessible, par rapport à une balise <img /> ou une extension xml
- Il faut utiliser un symbole pour ce qu'il signifie, pas ce qu'il évoque vaguement pour vous
- Il ne faut jamais utiliser une police qui substitue des symboles à la place des caractères attendus
- Avant d'utiliser une police dingbats, vérifiez que le symbole n'est pas déjà disponible officiellement en unicode
- Si vous utilisez une police qui crée ses symboles, vérifiez qu'ils sont bien définis dans les plans “usage privé” de l'unicode (principalement, U+E000 à U+F8FF), et pas en “réservé”, “expérimental” ou “non encore attribué”
- Il faut que les cibles (OS, bibliothèques et logiciels) acceptent des versions récentes de l'unicode si vous utilisez un symbole relativement récent
- Il faut que le système hôte client dispose de polices comportant les glyphes pour les nouveaux caractères (ou les fournir)
- Il faut que le système de rendu accepte les polices couleurs (si vous utilisez les variantes “enrichies”)
- Concernant le développement web : si vous faites des manipulations DOM, il faut que le javascript du navigateur manipule les chaînes de caractères en UTF-16 et pas en UCS-2. Ben oui, certains emoji sont placés largement au-delà de l'index U+10000. J'ai déjà un billet en écriture sur cette dernière surprise.
- Concernant le développement mobile sous Android, gaffe si votre code manipule en interne les chaînes en MUTF-8, puisque cela modifie le comportement d'affichage pour les points unicodes U+10000 à U+10FFFF. Une région plus proche du UTF-16 (c'est le mode CESU-8, compromis bizarre entre mémoire et optimisation pour l'embarqué) que de l'UTF-8 que vous attendiez.
Dans le doute, restez aux bonnes vieilles balises images, sans oublier bien sûr de renseigner l'attribut alt="" car il risque d'être significatif
Merci de votre lecture
Il convient de re-remercier pour leur aide indispensable :
- AperoWeb Toulouse et SudWeb pour m'avoir donner envie d'en faire une suite de billet, puis une conf
- Paul Rouget car il a proposé d'utiliser des webfonts dingbats, ce qui m'a fait sursauter
- Laurent et Rieko Nespouslous, amis précieux, qui sont repartis vivre au Japon
- Frédéric Boilet pour qui Tōkyō est un jardin
- mes contacts pros et du groupe Index au Japon, aux éditeurs Japonais avec qui j'ai eu l'honneur d'échanger et de travailler
- Dominique Vérêt et Erwan Leverger pour leur travail visionnaire
- Rafy, Sébastien et Claude Yoshizawa, car je désespère pas, grâce à eux, de pouvoir libérer des archives
Une grande partie du texte a été rédigé le 9 Février 2012 (!). Le plus dur, c'est parfois trouver les illustrations.
Mon blog n'a pas pour vocation de fournir un thesaurus, un dictionnaire ou un aide-mémoire sur les balises HTML, les astuces javascript ou les caractères Unicode. Mais j'estime qu'il était utile de faire ce travail.
…pour récolter vos visites (uhuhuhuhu).